Tips en Trucs 2009
LAMP is een letterwoord voor Linux, Apache, MySQL en PHP. Met de hier beschreven stap voor stap handleiding kan de Apache2 webserver op openSUSE 11.2 met PHP5 (mod_php) en MySQL ondersteuning geïnstalleerd worden. In het voorbeeld gebruik ik het IP adres 192.168.0.194. Deze instellingen kunnen bij u anders zijn, m.a.w. gebruik waar nodig uw eigen instellingen.
MySQL 5 installeren
Installeer MySQL met de opdracht: sudo zypper install mysql mysql-client
Daarna creëren we de systeemstart koppelingen voor MySQL (daardoor start MySQL automatisch bij het opstarten van het systeem) met de opdracht: sudo /sbin/chkconfig --add mysql
en starten we de MySQL server met de opdracht: sudo /etc/init.d/mysql start
Om de MySQL installatie te beveiligen, start je de opdracht sudo mysql_secure_installation
NOTE: RUNNING ALL PARTS OF THIS SCRIPT IS RECOMMENDED FOR ALL MySQL
SERVERS IN PRODUCTION USE! PLEASE READ EACH STEP CAREFULLY!
In order to log into MySQL to secure it, we'll need the current
password for the root user. If you've just installed MySQL, and
you haven't set the root password yet, the password will be blank,
so you should just press enter here.
Enter current password for root (enter for none): ENTER
OK, successfully used password, moving on...
Setting the root password ensures that nobody can log into the MySQL
root user without the proper authorisation.
Set root password? [Y/n] Y ENTER
New password: MySQL wachtwoord intypen ENTER
Re-enter new password: MySQL wachtwoord nogmaals intypen ENTER
Password updated successfully!
Reloading privilege tables..
... Success!
By default, a MySQL installation has an anonymous user, allowing anyone
to log into MySQL without having to have a user account created for
them. This is intended only for testing, and to make the installation
go a bit smoother. You should remove them before moving into a
production environment.
Remove anonymous users? [Y/n] Y ENTER
... Success!
Normally, root should only be allowed to connect from 'localhost'. This
ensures that someone cannot guess at the root password from the network.
Disallow root login remotely? [Y/n] Y ENTER
... Success!
By default, MySQL comes with a database named 'test' that anyone can
access. This is also intended only for testing, and should be removed
before moving into a production environment.
Remove test database and access to it? [Y/n] Y ENTER
- Dropping test database...
... Success!
- Removing privileges on test database...
... Success!
Reloading the privilege tables will ensure that all changes made so far
will take effect immediately.
Reload privilege tables now? [Y/n] Y ENTER
... Success!
Cleaning up...
All done! If you've completed all of the above steps, your MySQL
installation should now be secure.
Thanks for using MySQL!
Apache2 installeren
Apache2 is beschikbaar als een openSUSE pakket, en kan geïnstalleerd worden met de opdracht sudo zypper install apache2
Apache toevoegen aan het opstartproces van uw systeem doe je met de opdracht sudo /sbin/chkconfig --add apache2
Apache start je met de opdracht sudo /etc/init.d/apache2 start
Indien je de webserver Apache wilt testen vanaf een andere computer in hetzelfde netwerk, moet je de firewall voor Apache openen met de opdracht sudo /sbin/yast2 firewall services add zone=EXT service=service:apache2 (om Apache bereikbaar te maken via het internet moet je eveneens uw router instellen, doe dit pas nadat je 100% zeker bent dat uw systeem goed beveiligd is).
Surf naar http://192.168.0.194 en je ziet een Apache2 pagina (negeer de 403 error, dit is te wijten aan het ontbreken van een index bestand (vb: index.html) in de document root map)
Apache standaard document root map is op openSUSE /srv/www/htdocs/ en het configuratiebestand is /etc/apache2/httpd.conf.
Aanvullende configuraties worden opgeslagen in de map /etc/apache2/conf.d/.
PHP5 installeren
Installeer PHP5 en de Apache PHP5 module met de opdracht sudo zypper install apache2-mod_php5
Daarna moet je Apache herstarten met de opdracht sudo /etc/init.d/apache2 restart
PHP testen / PHP informatie opvragen
De root documentenmap van de standaard web site is /srv/www/htdocs/.
We maken in deze map een klein PHP bestand (info.php) aan en surfen ernaar met een browser.
Het bestand toont veel nuttige details over onze PHP installatie, zoals de geïnstalleerde versie.
Dit bestand kan je aanmaken met de opdracht echo "echo '' > /srv/www/htdocs/info.php" | sudo sh
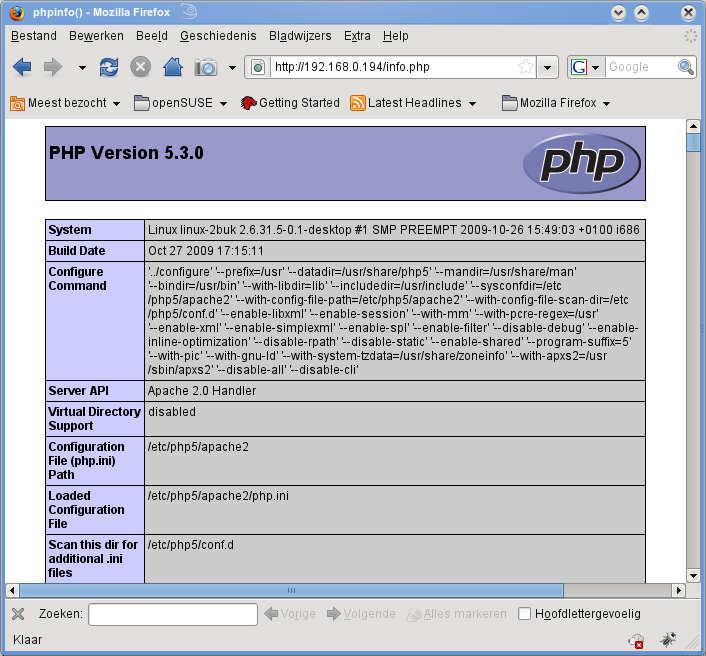
Zoals je kan afleiden uit de regel Server API werkt PHP via de Apache 2.0 Handler.
Verderop vind je de actieve PHP5 modules.
Daar MySQL niet in deze lijst staat, kan PHP nog geen gebruik maken van de MySQL databaseserver.
MySQL ondersteuning in PHP5 activeren
Om MySQL ondersteuning in PHP te activeren, installeer je het php5-mysql pakket.
Dit is het geschikte moment om nog enkele andere PHP5 modules voor uw applicaties te installeren: sudo zypper install php5-mysql php5-bcmath php5-bz2 php5-calendar php5-ctype php5-curl php5-dom php5-ftp php5-gd php5-gettext php5-gmp php5-iconv php5-imap php5-ldap php5-mbstring php5-mcrypt php5-odbc php5-openssl php5-pcntl php5-pgsql php5-posix php5-shmop php5-snmp php5-soap php5-sockets php5-sqlite php5-sysvsem php5-tokenizer php5-wddx php5-xmlrpc php5-xsl php5-zlib php5-exif php5-fastcgi php5-pear php5-sysvmsg php5-sysvshm
Herstart Apache met sudo /etc/init.d/apache2 restart
Vernieuw de http://192.168.0.194/info.php pagina in uw browser en bekijk opnieuw de sectie met de modules.
Daar vind je veel nieuwe modules, waaronder de MySQL module.
phpMyAdmin
phpMyAdmin is een web gebruikersomgeving om uw MySQL databases te beheren.
phpMyAdmin installeer je als volgt:
wget http://downloads.sourceforge.net/project/phpmyadmin/phpMyAdmin/3.2.4/phpMyAdmin-3.2.4-all-languages.tar.bz2?use_mirror=kent
sudo tar xjvf phpMyAdmin-3.2.4-all-languages.tar.bz2 -C /srv/www/htdocs/
sudo mv /srv/www/htdocs/phpMyAdmin-3.2.4-all-languages /srv/www/htdocs/phpmyadmin
Daarna kan je phpMyAdmin bereiken via de webpagina http://192.168.0.194/phpmyadmin
Marble is een geografisch kaarten programma, vergelijkbaar met Google Earth/Google Maps. Google Earth heeft 3D versnelling nodig, terwijl Marble geen speciale grafische eisen nodig heeft om zijn werk te vervullen, dus ook te gebruiken is op een virtuele computer met de meest eenvoudige grafische kaart en stuurprogramma.
Marble is beschikbaar voor alle belangrijke besturingssystemen. Er bestaan twee smaken, de QT en KDE versie. Deze laatste is de aanbevolen versie, omdat deze extra mogelijkheden heeft die ontbreken in de QT versie. De KDE versie bestaat ook als live CD.

OpenSUSE 11.2 bevat Marble standaard, andere distributies kunnen het eenvoudig installeren via hun standaard installatieprogramma.
Ik was ontzettend tevreden over Marbles uitzicht en gedrag, wat later nog verder bevestigd werd. Het programma is snel en reageert vlot zonder horten en stoten en dit ondanks het gebrek aan een 3D grafische versnelling.
Marble kent verschillende kaartbeelden, die allemaal verschillende resultaten opleveren.
Atlas
Het standaard gebruik is een geopolitieke kaart, met de voorstelling van de landen, hun grenzen en steden in de klassieke topografische kleuren.
Je kan de navigatieknoppen in het linkerpaneel gebruiken om te schuiven en te zoomen.
Slepen met de muis op de kaart kan eveneens.
Als je naar een bepaalde plaats op aarde wilt gaan, typ je in het zoekveld de plaatsnaam in.
Marble begint te zoeken naar plaatsen terwijl je typt.
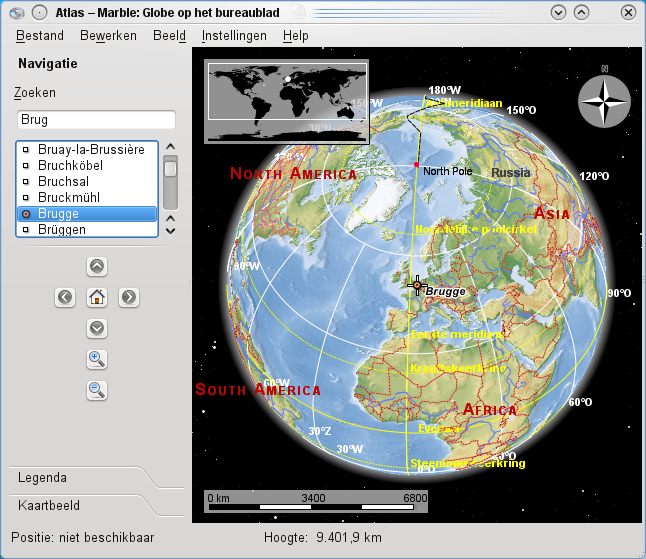
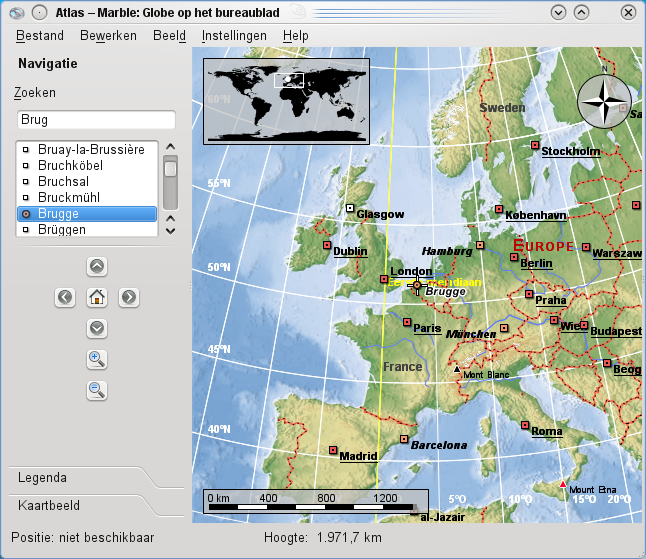
Plaatsgegevens
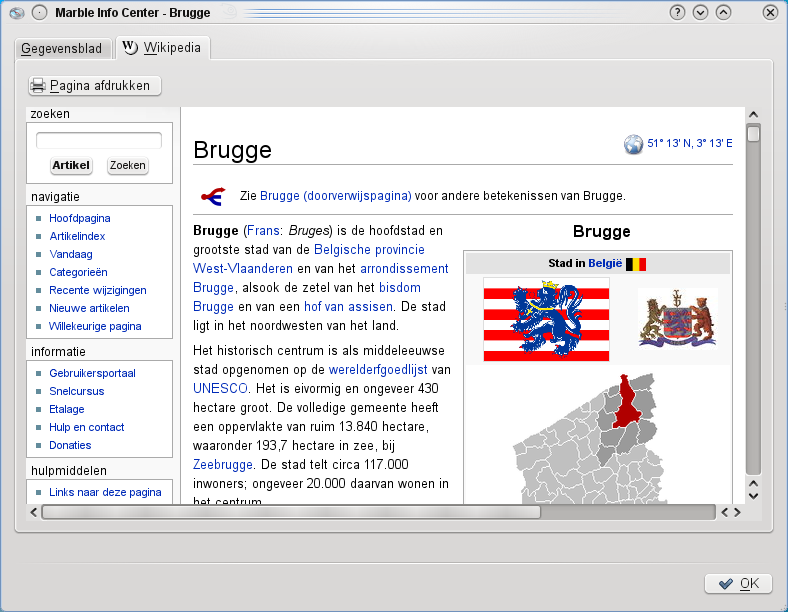
De kaarten zijn interactief. Klik op een willekeurige stad en je krijgt encyclopedische (wiki) gegevens over de aangeklikte stad, inclusief wapenschild, vlag, een historisch overzicht, afbeeldingen, enz. In dit opzicht is Marble een dynamische atlas.
Wegenkaart
Je kan de aarde ook bekijken in functie van het transportnetwerk. Deze wegenkaarten worden samengesteld aan de hand van gegevens van OpenStreetMap.
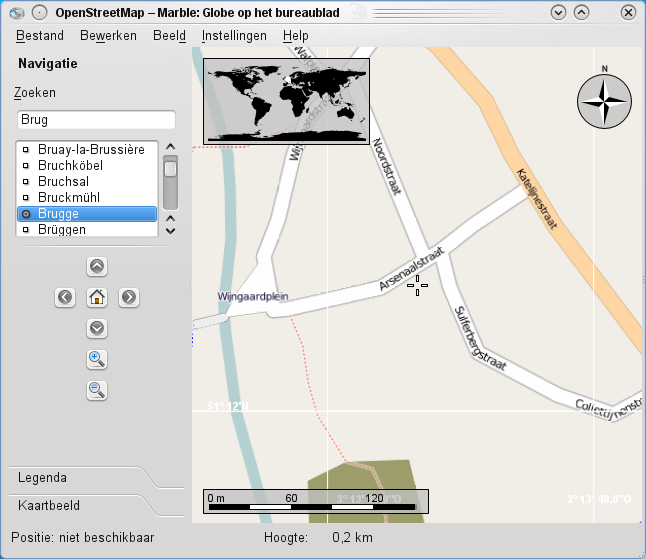
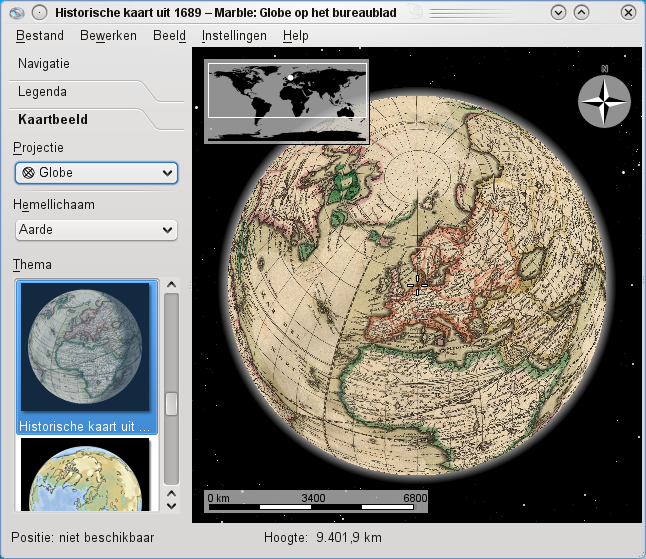
Historische kaarten
Of je kan zien hoe de mensen de aarde in het verleden zagen. Marble haalt bij het aanpassen van het kaartbeeld indien nodig de ontbrekende kaarten van het internet.
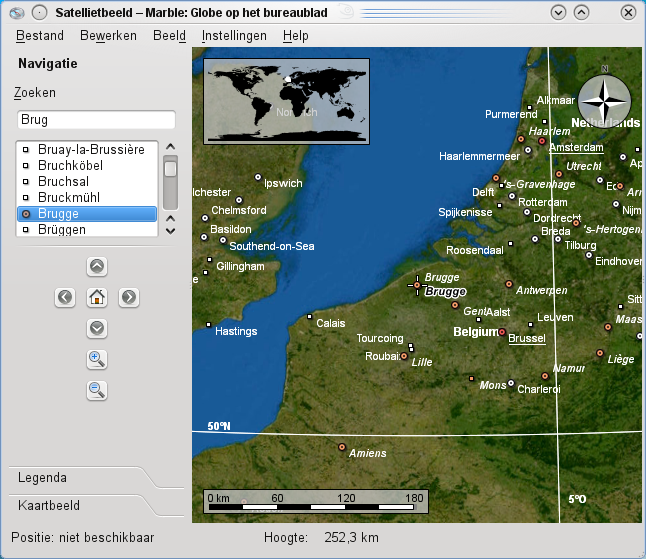
Satellietbeelden
Eén van de meest gewaardeerde functies van Marble zijn de satellietbeelden. Je kan inzoomen op elk onderdeel van de planeet en de authentieke satellietbeelden bekijken. Het is zo realistisch dat bij het bekijken van de aarde vanop grote hoogte de dampkring het onderliggende land (of water) bedekt met een wazige mist.
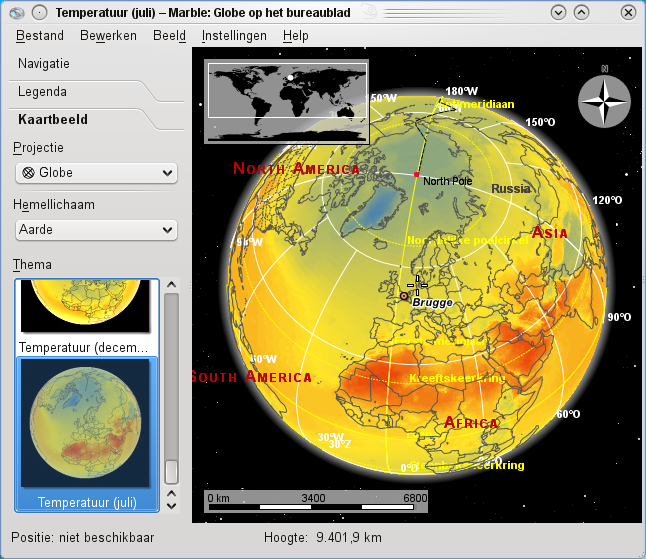
Klimaatkaarten
Je kan eveneens het klimaat op de aarde observeren (temperatuur en neerslag in de maanden juli en december).
M.a.w. Marble is een spectaculair stukje software. Het is mooi, zeer gedetailleerd, goed voorgesteld, snel, robuust en reageert vlot. Je kan er ook zonder krachtige grafische kaart van genieten, wat het nog wonderbaarlijker maakt. Voor mensen die aardrijkskundige interesse's hebben, is Marble een aanwinst. Ook voor leerkrachten (en hun leerlingen) is Marble een uitstekend hulpmiddel om de wonderen van onze planeet op een plezierige en spannende manier te tonen. Als extra kan je in KDE 4.3 Marble ook gebruiken als bureaubladachtergrond. Daarbij wordt de projectie regelmatig bijgewerkt, waardoor je een dynamisch bureaublad krijgt. Met andere woorden: Marble is fantastisch, een echte aanrader.
Gisteren moest ik nogmaals mijn repeterende trucs bovenhalen om een bestand te zoeken die in een groot aantal gecomprimeerde bestanden zat. Sommige bestanden eindigden op .tar.gz en andere op tgz. Ik wilde niet de volledige maand december opofferen om elk gecomprimeerd bestand te openen om te kijken of het bewuste bestand erin voorkomt. Ik maakte dus een opdrachtregel die de klus voor me kon klaren.
Eerste voorbeeld
( find /home/dany/test/ -iname '*'.tgz; find /home/dany/test/ -iname '*'.tar.gz; ) | while read filename; do lines=`tar tzf $filename | grep -i "pinda" | wc -l`; if [ $lines -gt 0 ]; then echo $filename; fi; done
De () zorgen ervoor dat je de uitvoer van verschillende opdrachten kunt verzamelen in één uitvoer.
De constructie while read variable; do x; y; z; done zorgt dat we elke regel uitvoer in een variabele (plaatshouder) kunnen opslaan (indien meerdere variabelen gebruikt worden, zal elke variabele een woord van de uitvoer bevatten).
In ons voorbeeld gebruiken we $filename als variabele (merk op dat je geen $ in de while read gebruikt).
De opdrachten tussen `` worden uitgevoerd en de uitvoer daarvan opgeslagen in een variabele. In ons geval overlopen we de inhoud van het gecomprimeerde bestand en doorzoeken het resultaat met grep naar het gezochte patroon, waarna we het aantal gevonden regels tellen. Het aantal gevonden regels wordt opgeslagen in de variabele $lines.
Uiteindelijk testen we of het gevonden aantal regels groter is dan 0. Indien dit het geval is, wordt de naam van het gecomprimeerde bestand waarin het gezochte patroon voorkwam op het scherm geplaatst.
Tweede voorbeeld
In dit voorbeeld gebruiken we ISO bestanden. Deze ISO bestanden bevatten RPM bestanden. In deze RPM bestanden gaan we op zoek naar een specifiek bestand.
In wezen is dit hetzelfde als in het eerste voorbeeld.
Het enige verschil zit hem in het extra koppelen van de ISO bestanden, waardoor we een extra niveau zullen moeten nesten (opdrachten binnen een constructie).
Daar enkel de root gebruiker een mount (koppel) opdracht kan uitvoeren, werkt het tweede voorbeeld enkel als je als root werkt (je kan in de terminal root worden met de opdracht su).
Daarnaast moet de map /mnt/tmp bestaan. Deze map kan je als root aanmaken met de opdracht mkdir /mnt/tmp.
Daar gaan we:
find /home/dany/test/ -iname '*'.iso | while read iso; do mount -o loop,ro $iso /mnt/tmp; find /mnt/tmp/-iname '*.rpm' | while read rpm; do lines=`rpm -qlp $rpm | grep -i "pinda" | wc -l`; if [ $lines -gt 0 ]; then echo $iso $rpm; fi; done; umount -l /mnt/tmp; done
Als je eenvoudige taken op bestanden wilt uitvoeren, kan je find vragen om opdrachten uit te voeren op de gevonden bestanden. In beide bovenstaande voorbeelden zou deze methode een berg vindingrijkheid vergen om de uit te voeren taken in de find werkwijze te integreren, vandaar dat ik koos voor de piping oplossing.

Daarnaast heb je een logo nodig. Je kan op verschillende manieren een logo voor graffiti ontwerpen. Wij gaan gebruik maken van tekst. Download dit graffiti lettertype en installeer het (rechts klikken op het uitgepakte lettertype > Acties > Install...). Start Gimp en open bovenstaande foto.
Gebruik het Gereedschap Tekst en typ de graffiti tekst in. Positioneer en zorg voor een passende grootte. Het perspectief verzorgen we later.
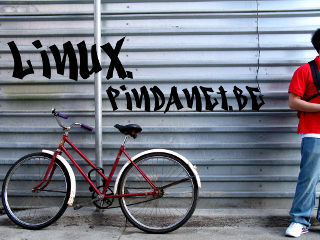
Selecteer de eerste tekstlaag en voeg deze samen met de tweede tekstlaag met het menu Laag > Neerwaarts samenvoegen. Verander de naam (dubbelklik) van de nieuwe laag naar "Tekst". Maak onder deze laag een nieuwe laag aan met de naam "Tekst_achtergrond". Klik met de rechtermuisknop op de Tekst laag en selecteer Alpha naar selectie. Gebruik het menu Selecteren > Uitdijen. Laat de selectie met 15 beeldpunten groeien. Selecteer de Tekst_achtergrond laag en vul de selectie met het Emmer Gereedschap op met wit.
Maak een nieuwe laag boven de Tekst laag aan en geef deze de naam "Tekst_verloop". Klik met de rechtermuisknop op de Tekst laag en selecteer Alpha naar selectie. Verander de voorgrondkleur (dubbelklik) naar #00a2ff en de achtergrondkleur naar #383838. Selecteer de Tekst_verloop laag en gebruik het Kleurverloop Gereedschap om een kleurverloop van de bovenste tekstrand naar de onderste tekstrand te slepen. Gebruik het menu Selecteren > Niets.
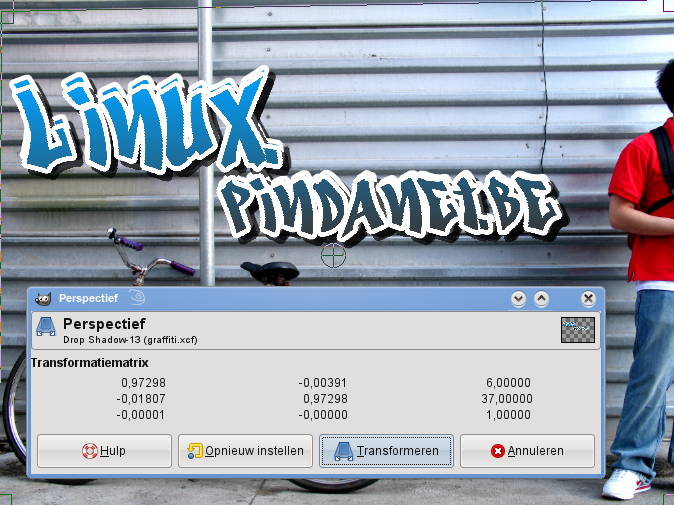
Voeg alle tekst lagen samen. Gebruik het menu Filters > Licht en schaduw > Drop Shadow... Gebruik als Verspringing X en Y 20 en als Vervagingsradius 0. Schakel Herschalen toestaan uit. Gebruik een Ondoorzichtigheid van 70. Klik OK. Voeg de tekst en schaduw laag samen. Het logo is klaar.
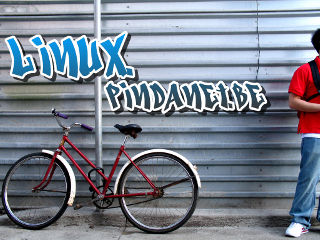
Gebruik het Perspectief Gereedschap. Pas het perspectief aan zodat het logo het perspectief van de muur volgt. Klik OK.
Verander de Modus van de logo laag naar Overheen leggen.
Het logo is te scherp om een logo te zijn. We gaan het vervagen. Dupliceer de logo laag. Plaats de kopie van de logo laag onder de originele logo laag. Gebruik het menu Filters > Vervagen > Gaussiaans vervagen... Gebruik een horizontale en vertikale vervagingsradius van 30 beeldpunten. Klik OK. Klik met de rechtermuisknop op de originele logo laag en selecteer Alpha naar selectie. Selecteer de gedupliceerde laag en druk op de Delete toets.

Gebruik het Gum Gereedschap om op de twee logo lagen de delen die de paal bedekken te wissen.

De afbeelding heeft nog een laatste effect nodig. Gebruik het menu Bewerken > Zichtbare kopiëren. Daarna gebruik je het menu Bewerken > Plakken als > New Layer. Gebruik op de nieuwe laag het menu Filters > Vervagen > Gaussiaans vervagen... Geef als horizontale en vertikale vervagingsradius 10 beeldpunten in. Klik OK. Gebruik als laag Modus Overheen leggen.

Zo kan je dus op een eenvoudige manier graffiti maken. Een laatste raadgeving: gebruik geen gladde muur - het effect komt alleen realistisch over op een ruwe muur met structuur.
VMware Player 3 verscheen onlangs en is naast de betere ondersteuning van hardware, host (besturingssysteem waaronder VMware werkt) en guest (in VMware geïnstalleerde besturingssystemen) vooral aangepast wat betreft de aanmaak van nieuwe virtuele computers. Je moet nu niet meer uitwijken naar afzonderlijke programma's of website's om een virtuele computer aan te maken. Dit kan nu ook rechtstreeks in de VMware Player zelf (misschien te danken aan de concurrent Virtualbox die dit al van in het begin kon).
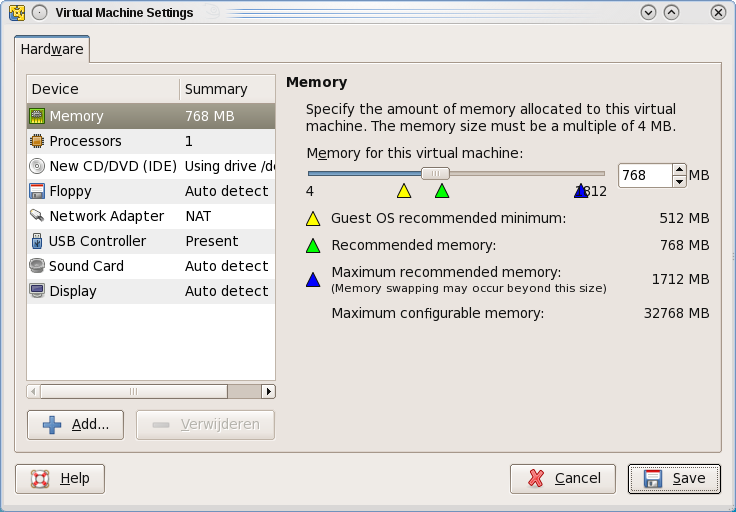
Om de nieuwe VMware Player op openSUSE te installeren onderneem je de volgende stappen:
- Haal de voor uw systeem geschikte bundle af (VMware Download). Het afgehaalde bundle bestand eindigd op .x86_64.bundle voor een 64-bits systeem en op .i386.bundle voor een 32-bits systeem.
- Start een terminal.
- Installeer het afgehaalde pakket met de opdracht
sudo sh Documents/Linux/VMware/VMware-Player-3.0.*.bundle.
Volg daarbij de instructies op het scherm. - Om VMware Player aan te passen aan het systeem heeft het extra onderdelen nodig.
Deze kan je installeren met de opdracht
sudo zypper install gcc kernel-source make.
Voor openSUSE 11.2 installeer je een extra onderdeel voor de desktop geoptimaliseerde kernel met de opdracht:sudo zypper install kernel-desktop-devel
- Start de VMware Player (K menu > Programma's > Systeem > Meer programma's > VMware Player). Volg de instructies van de VMware Player Assistent.
- Na de installatie van VMware kan je VMware opstarten. Maar bij het afsluiten van de computer en terug opstarten ervan krijg je bij het opstarten van een virtuele machine de foutmelding
Could not open /dev/vmmon. Dit kan je verhelpen door voor het opstarten van VMware de virtuele apparaten te herinitialiseren.- Grafische oplossing
- Maak in de Desktop-map (Bureaubladmap) een Nieuwe Link to application... (Koppeling naar programma...) aan (rechtermuisklik) met de volgende kenmerken:
- Tabblad Algemeen als Pictogram bij Toepassingen het pictogram vmware-player of vmware-workstation
- Tabblad Algemeen als naam in het tekstvak VMware Player (bij openSUSE 11.2 kan dit pas achteraf door de bestandsnaam te wijzigen).
- Tabblad Toepassing als Commando
kdesu "/etc/init.d/vmware restart"; vmplayer
vmplayerdoorvmware. - Terminal oplossing (voor openSUSE 11.2 vervang je /$USER/Desktop/ door /$USER/Bureaublad/)
echo '[Desktop Entry]' > /home/$USER/Desktop/VMware\ Player.desktop
echo 'Exec=kdesu "/etc/init.d/vmware restart"; vmplayer' >> /home/$USER/Desktop/VMware\ Player.desktop
echo 'Icon=vmware-player' >> /home/$USER/Desktop/VMware\ Player.desktop
echo 'StartupNotify=true' >> /home/$USER/Desktop/VMware\ Player.desktop
echo 'Terminal=false' >> /home/$USER/Desktop/VMware\ Player.desktop
echo 'Type=Application' >> /home/$USER/Desktop/VMware\ Player.desktop
echo 'X-DBUS-StartupType=none' >> /home/$USER/Desktop/VMware\ Player.desktop
echo 'X-KDE-SubstituteUID=false' >> /home/$USER/Desktop/VMware\ Player.desktop
echo 'X-SuSE-translate=true' >> /home/$USER/Desktop/VMware\ Player.desktop
- De bibliotheken nodig om VMware aan de kernel (systeem) aan te passen, kunnen nu verwijderd worden (mogen ook blijven staan, zie opmerking).
Daarbij zal meer dan 260 MB ruimte op de harde schijf vrijkomen.
Dit kan met met de opdracht
sudo zypper remove gcc kernel-source make(in openSUSE 11.2 mag ook kernel-desktop-devel verwijderd worden).
De VMware Player kan je van de computer verwijderen door de volgende stappen uit te voeren:
- Start een terminal.
- Start de opdracht
sudo vmware-installer --uninstall-product vmware-player.
Opmerking
Na een opwaardering (update) van de kernel via het internet, zal de VMware-player de onderdelen om zich aan de nieuwe kernel aan te passen automatisch hercompileren.
Heb je je ooit afgevraagt hoelang een proces reeds draait? Wist je hoe dit te bepalen? Wel, door de volgende opdracht uit te voeren weet je het:
dany@linux-sumi:~> ps aux | grep kmix | grep -v grep | ps -o etime `awk '{ print $2 }'`
ELAPSED
17:51
Indien er meer processen draaien met de gegrepte naam, wil je wat meer informatie tonen:
dany@linux-sumi:~> ps aux | grep kde | grep -v grep | ps -o pid,etime,cmd `awk '{ print $2 }'`
PID ELAPSED CMD
4385 11:30 /bin/sh /usr/bin/startkde
5012 11:23 kdeinit4: kdeinit4 Running...
5026 11:23 kded4
5476 11:15 kdeinit4: kio_file [kdeinit] file local:/tmp/ksocket-dany/klauncherNT5022.slave-socket local:/tmp/ksocket-dany/kio_desktopMT54
5505 11:00 /usr/bin/policykit-kde
5517 10:59 /home/dany/.kde4/Autostart/xbindkeys
Je kan zelf bepalen welke processen in de lijst worden opgenomen door andere argumenten met ps mee te geven. De te gebruiken argumenten kan je opzoeken met de opdracht:
man ps
Voor we starten hebben we een afbeelding nodig om een gekleurd gedeelte uit een gedesatureerde achtergrond te isoleren. De originele afbeeldingen (origineel en resultaat) kan je downloaden door op de verkleinde afbeeldingen hieronder te klikken. De originele afbeelding gaan we gebruiken om de tip stap voor stap uit te voeren.
De originele afbeelding
Het resultaat

Open de originele afbeelding in GIMP. Let op het Lagen-venster rechts op het scherm.
Dupliceer de laag Achtergrond door er rechts op te klikken en de opdracht Laag dupliceren uit te voeren.
Hernoem de laag naar Masker laag met behulp van een rechterklik en de opdracht Laagattributen bewerken...
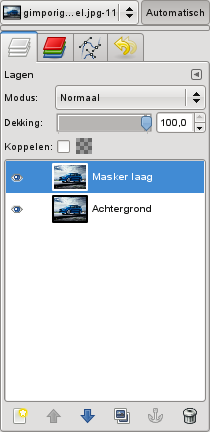
Nu we twee lagen aangemaakt hebben, gaan we de achtergrond desatureren. Merk op dat het effect alleen zal opvallen indien we de bovenste laag desatureren, m.a.w. de Masker laag.
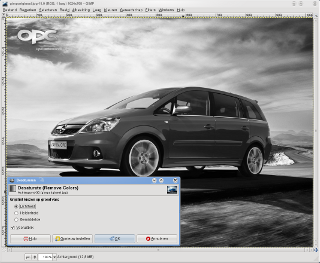
Om de desatureren gebruik je in het afbeeldingsvenster in het menu Kleuren de opdracht Desatureren... en klik je op de knop OK.
Daarna klik je met de rechtermuisknop op de bovenste laag (Masker laag) en voer je de opdracht Laagmasker toevoegen uit. Klik OK om een Wit (ondoorzichtig) masker toe te voegen.
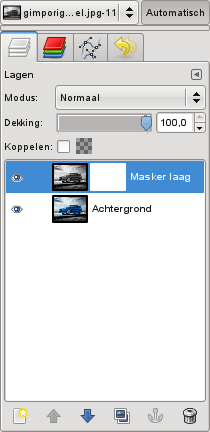
Merk het witte voorbeeld op juist naast de Masker laag, dit is het laagmasker dat je hebt toegevoegd. Al uw tekenwerk zal nu in dit masker doorgevoerd worden.
Gebruik het Penseel bij de Gereedschappen (linker venster) en vergroot de optie Schalen onder de Gereedschappen. Gebruik als voorgrondkleur zwart.
Gebruik het penseel op de plaatsen waar je kleuren wilt zien (de wagen). Schilderen met zwart maakt gaten in de bovenste laag, terwijl wit de gaten terug dichtmaakt.
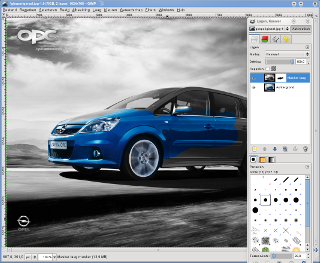
Fouten waardoor een deel van de achtergrond terug kleur krijgt, maak je ongedaan door de toetscombinatie CTRL+Z te drukken, of door de voorgrondkleur wit te kiezen en de foutieve delen met wit te overschilderen.
Merk op dat het tekenen wordt uitgevoerd in het masker. Eenmaal het voorwerp geïsoleerd is (in het voorbeeld de wagen), klik je met de rechtermuisknop op het masker en selecteer je de opdracht Laagmasker toepassen.
Klaar.
- in de terminal
- en vanaf versie 1.7 ook als grafiek
Deze laatste kan met behulp van een CGI script met een browser bekeken worden.
vnstat werkt via een cron taak die standaard om de vijf minuten wordt uitgevoerd. Deze taak verzamelt het netwerkverkeer voor de opgegeven netwerkverbindingen. vnstat verwerkt deze gegevens om u informatie te verschaffen over het dagelijkse, wekelijkse en maandelijkse netwerkverkeer.
Om vnstat te installeren, gebruik je de 1-Klik-installeren knop op de Software internet zoekpagina van openSUSE of via de terminal:
sudo zypper ar -r http://download.opensuse.org/repositories/server:/monitoring/openSUSE_11.1/server:monitoring.repo
sudo zypper refresh
sudo zypper install vnstat vnstat-cgi
Daarna start je de volgende opdracht om voor ten minste één netwerkverbinding een vnstat database aan te maken, waarbij je "eth0" kan vervangen door om het even welke verbinding die je wenst te monitoren:
sudo vnstat-create-db eth0
En klaar :)
Geef vnstat wat tijd (ten minste 5 minuten) om gegevens te verzamelen, en bekijk de resultaten in de terminal:
dany@linux-qgyf:~>Of surf met uw favoriete browser naar de URL: http://localhost/vnstat. Indien deze URL niet werkt, moet je de webserver apache met de volgende opdracht starten:vnstatDatabase updated: Sun Nov 1 20:35:01 2009 eth0 since 11/01/09 rx: 175.74 MiB tx: 2.56 MiB total: 178.30 MiB monthly rx | tx | total | avg. rate ------------------------+-------------+-------------+--------------- Nov '09 175.74 MiB | 2.56 MiB | 178.30 MiB | 19.71 kbit/s ------------------------+-------------+-------------+--------------- estimated 5.98 GiB | 69 MiB | 6.04 GiB | daily rx | tx | total | avg. rate ------------------------+-------------+-------------+--------------- today 175.74 MiB | 2.56 MiB | 178.30 MiB | 19.71 kbit/s ------------------------+-------------+-------------+--------------- estimated 204 MiB | 2 MiB | 206 MiB | dany@linux-qgyf:~>vnstat -heth0 20:35 ^ r | r | r | r | r | r | r | r | r | r -+---------------------------------------------------------------------------> | 21 22 23 00 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 h rx (KiB) tx (KiB) h rx (KiB) tx (KiB) h rx (KiB) tx (KiB) 21 0 0 05 0 0 13 0 0 22 0 0 06 0 0 14 0 0 23 0 0 07 0 0 15 0 0 00 0 0 08 0 0 16 0 0 01 0 0 09 0 0 17 0 0 02 0 0 10 0 0 18 0 0 03 0 0 11 0 0 19 0 0 04 0 0 12 0 0 20 179957 2620
sudo /usr/sbin/rcapache2 start
- Automatisch aanvullen van het adres: in plaats van het voorvoegsel http:// en achtervoegsel .com, .net of .org in de adresbalk te typen, kan je de naam van de website zoals slashdot typen en CTRL+SHIFT+Enter drukken om automatisch .org en http:// aan de URL toe te voegen. Op dezelfde manier druk je CTRL+Enter om .com en SHIFT+Enter om .net domeinnamen toe te voegen. Voorbeeld: typ google en druk CTRL+Enter om aan te vullen tot http://google.com.
- Soms typ je een fout in het webadres, of open je een verkeerde koppeling, die dan achteraf in het overzicht (uitschuifkeuzelijst adresbalk) van de automatishe aanvulling verschijnt. Deze verkeerd gespelde webadressen e.d.m. kan je uit de automatische aanvulling verwijderen door deze met de pijltoetsen te selecteren en Delete te drukken.
 Eén van de gaafste kenmerken van Firefox 3 is de verbeterde adresbalk, die u toelaat te zoeken naar websites in uw browsergeschiedenis en bladwijzers door in een willekeurige volgorde woorden in de adresbalk te typen.
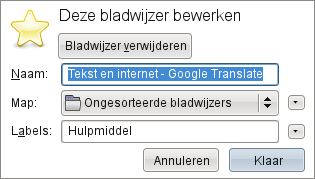
Je kan een bladwijzer van een website maken door op de grijze ster rechts in de adresbalk te klikken.
De ster wordt daardoor geel, en de bladwijzer is toegevoegd aan de ongesorteerde bladwijzers.
Klik op de gele ster, de bladwijzer knop, om de bladwijzer aan te passen, b.v. het verplaatsen van de bladwijzer naar een bepaalde bladwijzermap.
Je kan daarbij één of meerdere labels aan de bladwijzer toekennen, waardoor je deze labels in de adresbalk als zoekwoorden kunt gebruiken.
Eén van de gaafste kenmerken van Firefox 3 is de verbeterde adresbalk, die u toelaat te zoeken naar websites in uw browsergeschiedenis en bladwijzers door in een willekeurige volgorde woorden in de adresbalk te typen.
Je kan een bladwijzer van een website maken door op de grijze ster rechts in de adresbalk te klikken.
De ster wordt daardoor geel, en de bladwijzer is toegevoegd aan de ongesorteerde bladwijzers.
Klik op de gele ster, de bladwijzer knop, om de bladwijzer aan te passen, b.v. het verplaatsen van de bladwijzer naar een bepaalde bladwijzermap.
Je kan daarbij één of meerdere labels aan de bladwijzer toekennen, waardoor je deze labels in de adresbalk als zoekwoorden kunt gebruiken.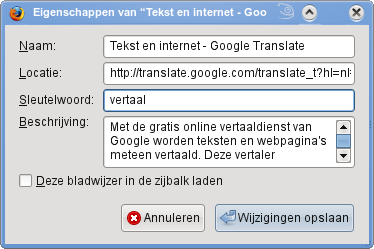 Uw favoriete websites bezoeken met behulp van bladwijzers vraagt heel wat muisklikken.
In de plaats daarvan kan je gebruik maken van sleutelwoorden.
Om sleutelwoorden aan een bestaande bladwijzer toe te kennen, klik je met de rechter muisknop op de bladwijzer en selecteer je Eigenschappen, typ een kort sleutelwoord (of een paar letters) in het betreffende tekstveld en klik OK.
Daarna kan je het sleutelwoord in de adresbalk als zoekwoord intypen om de site te bezoeken.
Uw favoriete websites bezoeken met behulp van bladwijzers vraagt heel wat muisklikken.
In de plaats daarvan kan je gebruik maken van sleutelwoorden.
Om sleutelwoorden aan een bestaande bladwijzer toe te kennen, klik je met de rechter muisknop op de bladwijzer en selecteer je Eigenschappen, typ een kort sleutelwoord (of een paar letters) in het betreffende tekstveld en klik OK.
Daarna kan je het sleutelwoord in de adresbalk als zoekwoord intypen om de site te bezoeken.- Wel eens een afbeelding of video van een website willen downloaden, waarbij bleek dat de pagina beschermd werd door de rechter muisklik en het opslaan als uit te schakelen. Door de broncode van zo'n site te analyseren kan je de afbeeldingen e.d. manueel afhalen. Er bestaat echter een veel eenvoudiger manier, klik daarvoor met de rechter muisknop op een willekeurige plaats op de webpagina en selecteer Pagina-info bekijken, ga naar het tabblad Media, selecteer de afbeelding die je wilt opslaan en klik op de Opslaan als... knop.
- De spellingcontrole van Firefox werkt standaard alleen in tekstgebieden, en om de spellingcontrole in tekstvakken te gebruiken, moet je deze activeren via de rechter muisklik op het tekstvak. Om dit standaard gedrag aan te passen, typ je in de adresbalk about:config en zoek je na de belofte dat je voorzichtig zult zijn op de verschenen webpagina naar layout.spellcheckDefault. Met een dubbelklik op layout.spellcheckDefault kan je waarde aanpassen naar 2, waardoor de spellingcontrole zowel werkt voor tekstvakken als voor tekstgebieden.
- Veronderstel dat je een verslag maakt, waarbij je enkele tekstfragmenten uit een weppagina nodig hebt. In plaats van elk tekstfragment appart te kopiëren en in de tekstverwerker te plakken, kan je het eerste tekstfragment selecteren, CTRL ingedrukt houden en een ander tekstfragment aan de selectie toevoegen. Daarna kan je in één kopieerbeweging de losse tekstfragmenten naar de tekstverwerker kopiëren. M.a.w. Firefox kan met meerdere selecties op een pagina werken.
- Slimme sleutelwoorden worden gebruikt om websites te doorzoeken via de adresbalk.
De werkwijze om slimme sleutelwoorden aan te maken staat beschreven op de Mozilla website.
Slimme sleutelwoorden zijn erg krachtig, naast het IMDB voorbeeld van Mozilla toon ik hoe de documentatie van wxWidgets op de site http://docs.wxwidgets.org/stable/ kan doorzocht worden.
Maak een slim sleutelwoord met de naam wxdoc vanuit google.be en pas de volgende eigenschappen manueel aan, via het bladwijzermenu verander je de Locatie eigenschap naar:
http://www.google.be/search?btnI=1&hl=nl&q=site:http://docs.wxwidgets.org/stable&q=%s
Daarna kan je door in de adresbalk wxdoc gevolgt door de API documentatie die je nodig hebt (voorbeeld: wxdoc wxAboutBox) via google de pagina met de documentatie opvragen. - Maak Gmail uw standaard E-mailclient: open uw Gmail inbox en typ onderstaande javascriptcode in de adresbalk en druk op de Return toets.
javascript:window.navigator.registerProtocolHandler("mailto","https://mail.google.com/mail/?extsrc=mailto&;url=%s","Gmail")
Bovenaan het browservenster verschijnt een balk met de vraag of je Gmail als programma voor de mailto-koppelingen wilt gebruiken. Klik op de knop Toepassing toevoegen om dit te bevestigen of klik op de X knop om het verzoek zonder aanpassingen te sluiten. - Je kan naar het volgende tabblad springen met de sneltoets CTRL+TAB of naar het vorige tabblad met CTRL+SHIFT+TAB.
- Sneller zoeken: naast het kopiëren en plakken van zoekwoorden vanuit een webpagina naar het zoekveld, kan je het geselecteerde zoekwoord naar het zoekveld slepen en laten vallen om de zoekactie te starten. Zet op de about:config pagina de waarde browser.search.openintab op true om de zoekresultaten in een nieuw tabblad te laten verschijnen.
- Heropen een pas gesloten tabblad met CTRL+SHIFT+T, open nieuwe tabbladen met CTRL+T. Rol de pagina naar beneden met de Spatiebalk en terug naar boven met SHIFT+Spatiebalk. Met CTRL++ zoom je in op de pagina, met CTRL+- terug uit, CTRL-0 zorgt voor een normale zoomfactor (100%). Klik met de middelste muisknop (wieltje) op een koppeling om deze in een nieuw tabblad te openen, op een tabblad met de middelste muisknop klikken, sluit het tabblad.
- De eigenschappen van popup-vensters kan je op de about:config pagina aanpassen:
dom.disable_window_open_feature.resizable
Zet deze waarde op true om de grootte van alle popup-vensters te kunnen wijzigen.
dom.disable_window_open_feature.minimizable
Zet deze waarde op true om alle popup-vensters minimaliseerbaar te maken.
dom.disable_window_open_feature.menubar
Zet deze waarde op true om de menubalk in alle popup-vensters te tonen.
dom.disable_window_open_feature.location
Zet deze waarde op true om de navigatie werkbalk in alle popup-vensters te tonen.
dom.disable_window_open_feature.scrollbars
Zet deze waarde op true om webpagina's te verhinderen de schuifbalken te verbergen.
Met trap kan je bash bij het ontvangen van een signaal opdrachten laten uitvoeren. Een nuttige toepassing is het opruimen van tijdelijke bestanden bij het afsluiten van een script.
Om een script bij het ontvangen van een signaal code te laten uitvoeren, gebruik je de volgende syntaxis:trap arg sigspec...Het arg gedeelde is de uit te voeren opdracht. Indien de opdracht spaties bevat, plaats je het tussen aanhalingstekens. Meerdere opdrachten worden gescheiden door puntkomma's. Voor complexe zaken, plaats je de code in een functie (function) en roep je de functie aan. Het sigspec gedeelte is een lijst van signalen waarop gewacht wordt om arg uit te voeren. Als voorbeeld, om een bestand bij het verlaten (EXIT) te verwijderen, gebruik je:
trap "rm -f bestand" EXIT
Merk op dat EXIT geen echt signaal is (gebruik de opdracht kill -l om alle signalen op te sommen); bash produceert het signaal EXIT kunstmatig bij het verlaten van het script.
trap "rm -f *.tmp" EXITzal de opdracht die wordt uitgevoerd
rm -f abc.tmp zijn en niet rm -f *.tmp.
Om dit te vermijden, gebruik je enkele aanhalingstekens.Indien je op verschillende plaatsen in uw code tijdelijke bestanden aanmaakt en je geen vaste regels gebruikt om de tijdelijke bestanden een naam te geven waardoor je jokers in de trap regel kunt gebruiken en je de trap definitie wil laten mee evolueren met uw code, kan je het volgende gebruiken om opdrachten aan de trap definitie toe te voegen:
#!/bin/bash declare -a on_exit_items function on_exit() { for i in "${on_exit_items[@]}" do echo "on_exit: $i" eval $i done } function add_on_exit() { local n=${#on_exit_items[*]} on_exit_items[$n]="$*" if [[ $n -eq 0 ]]; then echo "Trap instellen" trap on_exit EXIT fi } touch $$-1.tmp add_on_exit rm -f $$-1.tmp touch $$-2.tmp add_on_exit rm -f $$-2.tmp ls -la
De functie add_on_exit() voegt opdrachten toe aan een reeks, en bij het verlaten van het script doorloopt de on_exit() functie de reeks waarbij de verzamelde opdrachten uitgevoerd worden. De on_exit functie activeert de trap opdracht de eerste keer dat de functie add_on_exit wordt aangeroepen.
Veel KDE 3 gebruikers kennen KRun, een eenvoudig doch effectieve manier om opdrachten uit te voeren. Krun start door het drukken van de "Alt-F2" toetscombinatie en wordt gebruikt om op een eenvoudige manier programma's op te starten zonder de verschillende Kmenu submenu's te doorlopen of een terminal te starten. Het enige nadeel van de KDE 3 versie was dat je de exacte naam van de opdracht om het programma te starten moest kennen. Met de komst van KDE 4 veranderde dit echter grondig.
KRunner werkt onafhankelijk van het Plasma bureaublad systeem als een afzonderlijk programma. Het bevat een massa functies waardoor het meer kan dan het op een eenvoudige manier starten van opdrachten. Het behield daarbij veel van de in KDE 3 aanwezige functies en kreeg er heel wat nieuwe functies bij. Ziehier enkele opmerkelijke KRunner functies. Hoewel de schermafdrukken afkomstig zijn van KDE 4.3 (testversie openSUSE 11.2) werken deze functies ook in KDE 4.1 (openSUSE 11.1).
Rekenmachine
Als je na het betalen van de abonnementen van uw MMORPGs wilt weten hoeveel geld je nog over hebt om boodschappen te doen, druk je "Alt-F2" of klik je op het bureaublad met de rechtermuisknop en kies je Commando uitvoeren. Om KRunner als rekenmachine te gebruiken, typ je het = teken en daarna de berekening. Een voorbeeld, typ=890*12, en er verschijnt een pictogram van een rekenmachine en het antwoord: 10680.
Selecteer het resultaat om er verder mee te rekenen.
KDE 3 had een gelijkaardige functie, maar opende daarvoor Google's rekenmachine.
Nu kan je meerdere berekeningen uitvoeren zonder het KRunner venster te verlaten.
Eenheden converteren
Als je een reis plant naar de USA, waar de inwoners een eigen set eenheden hanteren, kan KRunner je bijstaan. Start KRunner en voer een getal in en een eenheid. Standaard wordt de eenheid omgezet naar meters. Voeg "in" of "als" toe gevolgd door een eenheid, en de omzetting wordt ogenblikkelijk zichtbaar. Als voorbeeld, typ5 mijl in cm en KRunner toont: 804672 centimeters. Werkt in openSUSE 11.1 enkel in het engels.
Contactpersonen zoeken
Als je vlug een e-mail bericht wilt sturen, typ je de naam van de persoon in uw adresboek (werkt alleen samen met KAddressBook). KRunner toont alle namen die lijken op wat je typte voorafgegaan door de tekst: Bericht sturen naar.Website bezoeken
KRunner kan elke website in uw standaard browser starten. Je kan ook gebruik maken van de Webkoppelingen van Konqueror. Een voorbeeld, om afbeeldingen i.v.m. pandas te zoeken op Google, gebruik je:images: pandas.
Daarbij wordt voor je Return drukt een knop zichtbaar met het opschrift: Google afbeeldingen zoeken doorzoeken voor pandas.
KRunner maakt eveneens gebruik van de Bladwijzers en de browser Geschiedenis om website's te zoeken.
Plaatsen openen
Om deze functie van KRunner te gebruiken, moet je in de Systeeminstellingen op het tabblad Geavanceerd in de module Desktop-zoekopdracht de Nepomuk Semantic Desktop en de Strigi Desktop Bestandenindexering activeren. Daarna kan door een naam van een map in KRunner op te geven de opgegeven map geopend worden. Om de standaard muziek map te openen, typ jeMusic. Zo eenvoudig is het. Nieuw in KDE 4.3 (openSUSE 11.2).
Desktop zoeken
Je hebt een Linux cursus geschreven en enkele weken terug omgezet naar PDF, maar je kan het PDF bestand niet terug vinden. Als je Strigi, KDE's desktop zoeksysteem, gebruikt, kan KRunner het bestand opzoeken. Typ de zoektermen in en laat het desktop zoeksysteem het werk doen. Nieuw in KDE 4.3 (openSUSE 11.2).Systeemactiviteit
Een lichte versie van ksysguard, KDE's Prestatiemonitor, is beschikbaar als een component van KRunner. Klik op het tweede pictogram in het KRunner venster of druk Ctrl-Esc om de Systeemactiviteitcomponent van KRunner te activeren. Zo kan je snel en eenvoudig de processorbelasting en geheugengebruik van processen en programma's volgen. Via de Systeemactiviteit kan je programma's geforceerd afsluiten. Voorzichtig gebruiken.Programma's zoeken en starten
Veronderstel dat je een kaartspel wil starten waarvan je de naam vergeten bent. Typkaart in KRunner en de kaartspellen verschijnen.
Als je de naam van een programma in KRunner intypt, toont KRunner alle programma's waarvan de naam begint met de reeds ingetypte letters.
Opdrachten uitvoeren
Naast alle nieuwe functies, blijft KRunner opdrachten uitvoeren en een geschiedenis bijhouden van de uitgevoerde opdrachten. De geschiedenis wordt zichtbaar bij het hertypen van een opdracht of door het openen van de vervolgkeuzelijst. Om de X server te configureren, typ jekdesu kwrite /etc/X11/xorg.conf en KRunner onthoudt de opdracht, mocht je deze later nog nodig hebben.
Het belangrijkste van KRunner is zijn uitbreidbaarheid. Veel van de hier vermelde plugins werden geschreven door gebruikers die niet tot het oorspronkelijke KRunner ontwikkel team behoren. Iedereen kan plugins schrijven, waardoor de mogelijkheden oneindig groot zijn. Indien je een plugin niet wenst te gebruiken, kan je die uitschakelen. Zo kunnen KDE 3 puristen terugkeren naar het oorspronkelijke doel van KRunner waarbij enkel het uitvoeren van opdrachten mogelijk was. Dit is ook belangrijk voor het gebruik op minder krachtige computers. Bij elke nieuwe versie van KDE, wordt KRunner niet alleen efficienter, maar komen er steeds meer fantastische functies bij.
Automatic Command-line Ripper (ACRipper) is een gratis opensource hulpmiddel om CD tracks te rippen en daarna te coderen. Daarbij wordt de CD informatie van freedb.org (een CDDB website) afgehaalt en in de gecodeerde bestanden opgeslagen. Indien freedb.org de informatie niet kan leveren, wordt de CD informatie (CD titel, artiest en track namen) gelezen uit het bestand “titles.txt” in de huidige map.
Samengevat, ACRipper is bedoeld om via de opdrachtregel eenvoudig en snel ogg bestanden aan te maken met track informatie. Naast de OGG codec worden de codecs FLAC en MP3 ondersteund.
In openSUSE kan je ACRipper installeren door op de website van Packman naar acripper te zoeken, waarna je door te klikken op de knop 1 click install de installatie assistent start. Open daarvoor het bestand acripper.ymp met de YaST-metapakketbehandelaar. Bevestig met de knop Verder de Softwarebeschrijving. Bevestig daarna de Installatie-instellingen. Bij de Installatie uitvoeren verschijnt een waarschuwing, lees deze en indien je de mogelijke gevolgen van de installatie aanvaard, klik je op de knop Ja. Geef het root wachtwoord op om de installatie te starten. Daarbij wordt de Packman softwarebron aan te softwarebronnen toegevoegd (daarvoor moet je de toestemming geven om een GnuGPG-sleutel te ïmporteren), wordt acripper en de afhankelijke pakketten afgehaald en geïnstalleerd. Daarbij moet je nogmaals toestemmen met een leveranciersverandering voor het afhankelijke pakket lame (nodig voor het aanmaken van mp3 bestanden). Accepteer uiteindelijk de installatie. Deze procedure kan door vroegere Packman installaties, uitgevoerde updates e.d.m. iets afwijken van de hier beschreven installatieprocedure. De installatie assistent volgen en de dialoogvensters aandachtig lezen, zorgt echter telkens voor een geslaagde installatie.
ACRipper is een handig hulpmiddel.
Plaats een audio CD in het station en start acripper in een terminal venster.
Dit zal standaard een verbinding met de freedb.org website maken om de CD informatie op te halen en indien de informatie niet gevonden wordt, wordt de betreffende informatie uit het indien aanwezige bestand titles.txt gehaald.
Daarna start het rippen van de CD en het coderen naar het ogg formaat (standaard).
dany@linux-qgyf:~> acripper
ACRipper v1.2
Olivier Meurice 2007
See ACRipper home page at <http://sourceforge.net/projects/acripper>
CD contains 7 track(s)
--> Try to connect to freedb.org...
CD title: Morehead
Artist name: Gabriel Rios
Genre: Alternative
Ripping and encoding track 1 [Voodoo Chile] to [Voodoo_Chile.ogg]
Opening with wav module: WAV file reader
Encoding standard input to
"Voodoo_Chile.ogg"
at quality 6,00
[ 6,2%] [ 1m15s remaining] |
Je kan coderen naar het flac of mp3 formaat met behulp van het -e argument.
dany@linux-qgyf:~> acripper -e mp3
ACRipper v1.2
Olivier Meurice 2007
See ACRipper home page at <http://sourceforge.net/projects/acripper>
CD contains 7 track(s)
--> Try to connect to freedb.org...
CD title: Morehead
Artist name: Gabriel Rios
Genre: Alternative
Ripping and encoding track 1 [Voodoo Chile] to [Voodoo_Chile.mp3]
LAME 3.99 (alpha 1, Sep 1 2009 11:08:59) 32bits (http://www.mp3dev.org/)
warning: alpha versions should be used for testing only
CPU features: MMX (ASM used), SSE (ASM used), SSE2
Using polyphase lowpass filter, transition band: 16538 Hz - 17071 Hz
Encoding <stdin> to Voodoo_Chile.mp3
Encoding as 44.1 kHz j-stereo MPEG-1 Layer III (11x) 128 kbps qval=2
Ripping and encoding track 2 [Baby Lone Star] to [Baby_Lone_Star.mp3]
ACRipper is een snelle en eenvoudige Audio Ripper zonder opgeblazen grafische omgeving. Bezoek voor meer informatie de ACRipper's project website.
De twee hier beproken programma's voeren een omvangrijke en gedetailleerde analyse van uw computer uit en tonen daarna de gevonden informatie van de hardware, software, netwerkconfiguratie, enz. op het scherm. Als extra moesten de gereedschappen grafisch bestuurd kunnen worden (GUI).
lshw met een grafische gebruikers omgeving (GUI)
lshw (Hardware Lister) toont gedetailleerde informatie over de hardware configuratie van de computer. Het rapporteert op DMI-ondersteunende x86 of EFI (IA-64) systemen en op sommige PowerPC computers (PowerMac G4) de exacte geheugenconfiguratie, firmware versie, moederbord configuratie, CPU versie en snelheid, cache configuratie, bus snelheid, enz.
Vereisten:
- Linux kernel 2.4.x of 2.6.x
- een op PA-RISC, Alpha, IA-64 (Itanium), PowerPC of x86 gebaseerde computer
- een voorgecompileerd rpm/dep pakket of de broncode met een ANSI C++ compiler (getest met GCC 2.95.4 and 3.2.2) en voor de (optionele) GTK+ grafische gebruikers omgeving heb je een complete GTK+ 2.4 ontwikkelomgeving nodig (gtk2-devel)
De informatie kan uitgevoerd worden in tekst, XML of HTML formaat.
Voor het ogenblik wordt DMI (x86 en EFI), OpenFirmware device tree (PowerPC), PCI/AGP, ISA PnP (x86), CPUID (x86), IDE/ATA/ATAPI, PCMCIA (enkel getest op x86), USB and SCSI ondersteund.
Bij openSUSE 11.1 kan je voor de installatie gebruik maken van de site http://software.opensuse.org/search door te zoeken naar lshw en via een klik op de 1-Click Install knop van het pakket lshw-gui het pakket lshw-gui installeren. Daarbij wordt het afhankelijke pakket lshw automatisch meegeïnstalleerd.
Start het programma via KMenu > Programma's > Systeem > Configuratie > Hardware Diagnostics. Dubbelklik op de items om door de verschillende onderdelen te navigeren en zo de betreffende informatie van het onderdeel op te vragen.
HardInfo
HardInfo kan informatie achterhalen en sneheidsmetingen uitvoeren. In openSUSE kan je HardInfo installeren zoals lshw, via de site http://software.opensuse.org/search, waarna je het programma kan starten via KMenu > Programma's > Systeem > Monitor > System Profiler and Benchmark.
Het toont informatie over de volgende onderdelen:
- Processor
- Besturingssysteem
- Taal
- Opnemers (Sensors)
- Bestandssystemen
- Gedeelde mappen
- Beeldscherm
- Netwerkaansluitingen
- Omgevingsplaatshouders (Environment Variables)
- Gebruikers
- Kernel onderdelen (modules)
- PCI apparaten
- USB apparaten
- Printers
- Invoerapparaten
- Opslag
- Geheugen
- Blowfish versleuteling
- CryptoHash controlegetal berekening
- rij van Fibonacci berekening
- een oplossing voor de N-Queens puzzel
- het omzetten van een 3D-scene in een tweedimensionaal beeld (Raytracing)
- een snelle Fouriertransformatie (FFT)
Binnenkort verschijnt Moblin 2.0 voor netbooks en openSUSE 11.2. Wie nu reeds een glimp wil opvangen van deze nieuwe distributies kan de iso-bestanden downloaden en gebruiken. Deze iso-bestanden zijn soms gigabytes groot en evolueren nog volop. Er bestaan methoden om deze grotere bestanden efficiënt (lees snel) af te halen. M.a.w. we gaan het downloaden wat oppeppen.
Gebruik metalinks
Gebruik de "metalink" van een softwarebron, bijvoorbeeld de Milestone 7 van openSUSE 11.2
De opdracht aria2c http://download.opensuse.org/distribution/11.2-Milestone7/iso/openSUSE-KDE4-LiveCD-Build0271-i686.iso.metalink zal het bestand openSUSE-KDE4-LiveCD-Build0271-i686.iso van verschillende computers (mirrors) tegelijkertijd downloaden.
Als je in de browser op de koppeling mirror van het te downloaden bestand klikt, krijg je meer informatie over de beschikbare mirrors die het betreffende bestand aanbieden.
Zo kon het in dit voorbeeld gebruikte iso bestand van één mirror in België (zeer dicht en dus sneller), van 53 mirrors in Europa (iets verder, maar nog steeds snel) en 21 mirrors in de rest van de wereld (ver en dus trager).
Het iso-bestand kan dus van in totaal 75 verschillende computers op het internet gedownload worden.
De uitvoer van de opdracht:
2009-09-19 14:56:03.809821 NOTICE - Download afgerond: ./openSUSE-KDE4-LiveCD-Build0271-i686.iso.metalink 2009-09-19 14:56:04.406584 NOTICE - Download afgerond: [MEMORY]/openSUSE-KDE4-LiveCD-Build0271-i686.iso.torrent *** Download Progress Summary as of Sat Sep 19 14:57:17 2009 *** ====================================================================================================================================================== [#3 SIZE:24.5MiB/667.0MiB(3%) CN:43 SPD:407.76KiB/s UP:6.63KiB/s(170.6KiB) ETA:26m53s] FILE: ./openSUSE-KDE4-LiveCD-Build0271-i686.iso ------------------------------------------------------------------------------------------------------------------------------------------------------ [#3 SIZE:36.1MiB/667.0MiB(5%) CN:17 SPD:386.40KiB/s UP:10.04KiB/s(512.0KiB) ETA:27m51s]toont dat niet alleen mirrors gebruikt worden, maar dat indien mogelijk ook gebruik wordt gemaakt van het torrent peer to peer netwerk. De SPD waarde toont de snelheid waarmee het bestand afgehaald wordt (hier rond de 400 KiB/s, wat tegen de bovengrens van de gebruikte internetverbinding ligt.
Wie liever grafisch werkt, kan met Konqueror naar de softwarebron surfen, rechts klikken op de koppeling metalink van het te downloaden bestand en Openen met KGet (de downloadmanager van KDE 4).
Na het installatie van de Add-on DownThemAll! in Firefox kan je met een rechterklik op de koppeling metalink van het te downloaden bestand via Koppeling opslaan met DownThemAll! het bestand afhalen.
Gebruik RSync
Na het downloaden van het in het voorbeeld gebruikte iso-bestand, verschijnt een nieuwe versie. Dat niet alle onderdelen van een distributie (lees iso-bestand) daarbij aangepast werden is duidelijk. M.a.w. enkel de aangepaste onderdelen in het iso-bestand moeten afgehaald worden. Werkwijze om enkel de aanpassingen te downloaden:- Maak gebruik van uw favoriete (lees snelste, meestal de dichtste) mirror die rsync ondersteund (lijst met softwarebron-mirrors).
- Controleer de beschikbaarheid van het bestand met de opdracht:
rsync rsync://ftp.halifax.rwth-aachen.de/opensuse/distribution/11.2-Milestone7/iso/ - Kopieer het oude bestand met als naam de exacte naam van het nieuwe bestand.
Als voorbeeld neem ik de fictieve nieuwe build versie 0280.
cp openSUSE-KDE4-LiveCD-Build0271-i686.iso openSUSE-KDE4-LiveCD-Build0280-i686.iso - Start rsync om de aanpassingen op te halen:
rsync -avP rsync rsync://ftp.halifax.rwth-aachen.de/opensuse/distribution/11.2-Milestone7/iso/openSUSE-KDE4-LiveCD-Build0280-i686.iso .
De spatie gevolgt door een punt op het einde hoort bij de opdracht.
Dit zal alleen de aangepaste onderdelen downloaden, in sommige gevallen zijn dat maar enkele MB's, i.p.v. een paar GB's.
ntop is een open source netwerkverkeer sonde om het gebruik van een netwerk te onderzoeken. ntop maakt gebruik van libpcap en werkt op Linux/Unix en Windows besturingssystemen. ntop gebruikt webpagina's om door de netwerkverkeer informatie te bladeren en om een overzicht te krijgen van de toestand van het netwerk.
ntop toont het huidige netwerk gebruik, een lijst met de op het netwerk aangesloten computers en rapporten over het IP en Fibre Channel (FC) verkeer van de computer. ntop ondersteunt TCP/UDP (HTTP/FTP, DNS, Telnet, SMTP etc), ICMP, ARP & RARP, IP/IPX, DLC, Decnet, Apple Talk, Netbios, FC (Control Traffic - SW2, GS3, ELS & SCSI)
Bij de installatie (in openSUSE 11.1 met Software installeren) wordt gewezen op het aanmaken van een wachtwoord voor de admin ntop gebruiker.
Dit doe je met de opdracht sudo ntop -A -u wwwrun, waarbij je het wachtwoord tweemaal moet ingeven.
Start ntop met de opdracht
dany@linux-qgyf:~> sudo /usr/sbin/rcntop start
Starting service ntop doneDe web gebruikersomgeving is dan bereikbaar via http://localhost:3000 of http://<ipadres>:3000. Later kan je ntop stoppen met de opdracht
dany@linux-qgyf:~> sudo /usr/sbin/rcntop stop
Stopping service ntop done
Vanaf het ogenblik dat je op de webpagina aangemeld bent, worden alle gegevens in eenvoudige op computer/IP of protocol gebaseerde tabellen, taartdiagrammen en/of grafieken getoond. Enkele voorbeelden:
Als je mooie op RDD Tools gebaseerde grafieken wilt gebruiken, moet het pakket RDDTool (gaat in openSUSE automatisch bij het installeren van ntop) geïnstalleerd zijn.
Indien RDD Tools niet op de computer aanwezig is, krijg je bij het opstarten van ntop een foutmelding en schakelt ntop het gebruik van RRD Tools uit, waardoor geen op RDD gebaseerde grafieken mogelijk zijn.
Een paar voorbeelden van op RDD Tools gebaseerde grafieken:
De plugin architectuur maakt het eenvoudig om mogelijkheden toe je voegen, zoals netFlow/sFlow ondersteuning waarmee ntop de verkeersstromen in het netwerk zichtbaar maakt, onlangs opgemerkte pakketten van een bepaalde computer en ICMP verkeersstromen.
Klik op de Yes/No hyperlink om een plugin in- of uit te schakelen.Via de webpagina kan je de netwerkgegevens in verschillende formaten opslaan om deze verder te bestuderen en/of door andere programma's te laten verwerken.
ntop is het open source gereedschap voor elke netwerk- of systeembeheerder die een netwerk van om het even welke omvang moet beheren en zelfs voor uw thuisnetwerk. Bezoek eveneens de projectsite op http://www.ntop.org/news.html
lsof is een hulpmiddel om geopende bestanden op te sporen. Dit is bijzonder praktisch daar in Linux alles als bestanden benaderd wordt: verbindingen (pipes), mappen, apparaten, inodes, aansluitingen (sockets), enz.
lsof (zonder argumenten) toont alle geopende bestanden die door werkende processen gebruikt worden.
Om dit te beperken tot de processen gebruikt door een bepaalde gebruiker, gebruik je lsof -u gebruikersnaam.
Je krijgt dan bijvoorbeeld:
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME startkde 4555 dany cwd DIR 8,6 4096 6463490 /home/dany startkde 4555 dany txt REG 8,6 715072 5734406 /bin/bash startkde 4555 dany 0r CHR 1,3 0t0 2335 /dev/null gpg-agent 4782 dany 3r FIFO 0,7 0t0 12745 pipe gpg-agent 4782 dany 5u unix 0xffff88021e244980 0t0 12747 /tmp/gpg-XSsT5p/S.gpg-agent ssh-agent 4794 dany cwd unknown /proc/4794/cwd (readlink: Permission denied)De FD kolom toont de bestandsomschrijving (file descriptor) informatie of de identificatie voor andere bestandstypes. In het voorbeeld wijst cwd op de huidige map (current working directory) en txt wijst op programma tekst. De TYPE kolom toont bestandstype informatie, REG wijst op een gewoon (regular) bestand. De NODE kolom kan gebruikt worden om een verwijderd bestand terug te halen. Raadpleeg de man pagina's voor een volledige uitleg over de uitvoer.
lsof bestandsnaam toont welke processen dit bestand gebruikt.
lsof +D /map toont de processen die bestanden in deze map gebruiken.
Je kan dit gebruiken als je bij het loskoppelen (umount) van een bestandssysteem de foutmelding "apparaat is bezig" krijgt om te bepalen welke processen geopende bestanden op het bestandsysteem gebruiken.
Deze processen kan je dan afsluiten (al dan niet geforceerd).
lsof -c procesnaam toont alle processen waarvan de naam begint met procesnaam met geopende bestanden; lsof -p PID doet hetzelfde maar voor een bepaald proces ID.
Gebruik lsof -i om informatie over IP aansluitingen te krijgen.
Raadpleeg de man pagina's voor meer details en de vele niet behandelde argumenten.
Als je met meer dan één computer werkt, moet je de computers regelmatig synchroniseren om ze up to date te houden. Als extra wil je waarschijnlijk de synchronisatie ook vanop afstand uitvoeren; bijvoorbeeld als je op reis gaat met uw draagbare computer, wil je wat je er ook op doet backuppen op de computer thuis of op het werk (uw draagbare computer kwijt raken is niet plezant, maar al uw werk erop ook kwijtraken is nog minder plezant). Er bestaan meerdere oplossingen voor dit probleem: in deze tip introduceer ik het hulpmiddel rsync en enkele afgeleide hulpmiddelen, waarmee je op een eenvoudige manier kunt synchroniseren.
Wat is rsync?
Het rsync hulpmiddel is een bestands-uitwisselings en synchronisatie programma voor Linux en Unix (en omgezet voor Windows). Zijn belangrijkste kenmerk is een snelle manier om gegevens tussen twee computers uit te wisselen. Daarbij worden enkel de verschillen tussen de twee te synchroniseren bestanden verzonden, waardoor de verbinding minimaal belast wordt. Bij het gebruik van FTP (File Transfer Protocol) en hulpmiddelen zoals rcp of scp, worden de bestanden volledig verzonden, zelfs als er maar één byte verschillend is. Rsync is niet beperkt tot bestaande bestanden, maar kan ook overweg met bestanden en mappen die enkel aan één kant van de verbinding aanwezig zijn. En tenslotte wordt de communicatie geoptimaliseerd door de gegevens te comprimeren, waardoor je rsync zelfs zonder breedbandverbinding kunt gebruiken.
De meeste distributies installeren rsync standaard of kan het met behulp van het standaard Software installatie hulpmiddel geïnstalleerd worden. Voor versleutelde (beveiligde) verbindingen heb je het eveneens het standaard hulpmiddel ssh nodig. Daarnaast zorg je dat de firewall de verbinding tussen de twee computers toelaat (rsync gebruikt de TCP poort 873, ssh poort 22).
RSync gebruiken
We starten met het synchroniseren van een map op de broncomputer met een map op de doelcomputer. Dit kan met de opdracht:
rsync --compress --recursive --delete --links \
--times --perms --owner --group \
--verbose --progress --stats \
--rsh="ssh" \
--exclude "*bak" --exclude "*~" \
/map/op/de/broncomputer/* doelcomputer:/een/map/op/de/doelcomputer
rsync -zrltpogve "ssh" --progress --stats --delete \
--exclude "*bak" --exclude "*~" \
/map/op/de/broncomputer/* doelcomputer:/een/map/op/de/doelcomputer
Het --recursive (-r) argument zorgt dat rsync alle onderliggende mappen eveneens synchroniseert. Alle bestanden in een map, inclusief andere mappen en hun inhoud worden gesynchroniseerd. Indien je deze functionaliteit niet nodig hebt, zorgt het --dirs (-d) argument voor een tegenovergestelde effect: mappen en hun inhoud worden niet gesynchroniseerd.
Standaard zal rsync bestanden naar de doelcomputer kopiëren, maar zal geen bestanden op de doelcomputer verwijderen. Door het argument --delete te gebruiken zullen de bron- en doelmap exacte kopies van elkaar zijn. Pas op met lege bestanden: een leeg bestand synchroniseren met een doelmap, zal alles in deze doelmap verwijderen!
Als er koppelingen in de bronmap staan, worden deze koppelingen in de doelmap aangemaakt indien het argument --links (-l) gebruikt wordt. Een alternatief is gebruik maken van het argument --copy-links (-L) waardoor de gekoppelde bestanden naar de doelmap gekopiëerd worden. Wanneer er koppelingen verwijzen naar bestanden of mappen buiten de te synchroniseren map (veiligheidsrisico), gebruik je het argument --copy-unsafe-links. Het argument --safe-links negeert deze koppelingen en is daardoor veiliger.
De volgende vier argumenten --times, --perms, --owner en --group of -tpog bewaart de originele tijdstempel, rechten, gebruiker en groep eigenschappen. Deze argumenten kan je samen met de argumenten --recursive en --links vervangen door het ene argument --archive (-a). Voor puristen, het -a argument kan extra elementen kopiëren als je rsync op de doelcomputer als root uitvoert, wat uit veiligheidsoverwegingen afgeraden wordt. De opdracht wordt dan:rsync -zae "ssh" --delete --exclude "*bak" --exclude "*~" \
/map/op/de/broncomputer/* doelcomputer:/een/map/op/de/doelcomputer
De drie volgende argumenten --verbose, --progress en --stats zorgen voor informatie over wat rsync aan het doen is. Laat deze argumenten weg als je daar geen behoefte aan hebt, rsync meld dan alleen nog fouten.
Als je rsync gebruikt, moet je telkens een wachtwoord voor de doelcomputer opgeven.
Bij manueel gebruik is dit misschien vervelend, maar bij het gebruik van rsync in cron (takenplanner) blijft rsync wachten op het in te geven wachtwoord.
Om wachtwoordloze rsync sessies toe te laten heb je een publiek-privaat sleutelpaar nodig.
Voer daarvoor op de broncomputer de opdracht ssh-keygen -t rsa uit.
Geef daarbij geen wachtzin (passphrase) in.
Deze opdracht maakt een paar bestanden in de verborgen ~.ssh map: id_rsa en id_rsa.pub.
Meld je aan op de doelcomputer en voer in de persoonlijke map de opdrachten mkdir .ssh; chmod 0700 .ssh.
Ga terug naar de broncomputer en kopiëer het id_rsa.pub bestand als authorized_keys2 naar de nieuwe .ssh map.
Dit kan vanaf de broncomputer met de opdracht scp .ssh/id_rsa.pub gebruiker@doelcomputer:.ssh/authorized_keys2.
Klaar! Vanaf nu, kan je een ssh-verbinding naar de doelcomputer opbouwen (en scp of rsync gebruiken) zonder een wachtwoord op te geven.
Het argument --exclude en aanverwante --include zorgt voor selectief synchroniseren. In het voorbeeld worden de standaard backup bestanden uitgesloten. Door zelf bestanden uit te sluiten en op te nemen kan je de te verzenden bestanden optimaliseren.
Uiteindelijk volgen de bron en doelpaden. Vergeet daarbij /* niet, of het resultaat is niet wat je beoogde. Raadpleeg de documentatie als je het verschil tussen een/map, een/map/ en een/map/* wilt achterhalen. /* gebruiken is de veiligste manier.
Om een overzicht van alle rsync argumenten te krijgen, gebruik je de opdrachten rsync --help en man rsync.
Grafische alternatieven
Als opdrachten intypen niet uw ding zijn of je liever met de muis opdrachten geeft, zijn er verschillende mogelijkheden. Er bestaat echter geen perfect alternatief, m.a.w. onderwerp het programma aan een grondige test, voor je het intensief gaat gebruiken. Sommige programma's zijn nog in een ontwikkelingsstadium (maar interressant genoeg om hier te bekijken), sommige hebben geavanceerde mogelijkheden en er zijn zelfs waardeloze programma's bij (worden vermeld met een waarschuwing).
 GAdmin-Rsync
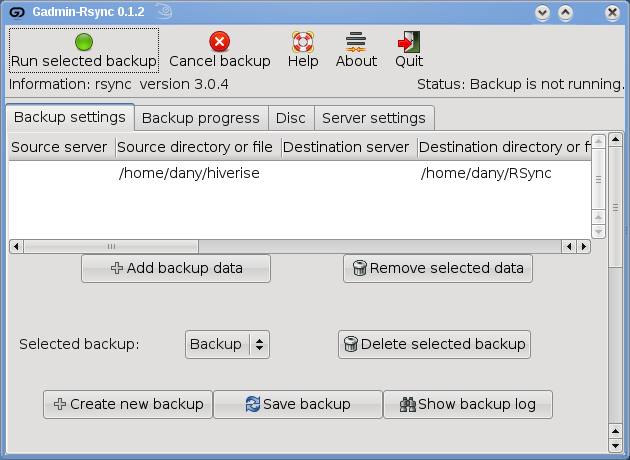
GAdmin-Rsync
GAdmin-Rsync is een onderdeel van het Gadmintools pakket, een set grafische GPL hulpmiddelen voor het beheer van Linux systemen.
De laatste versie (0.1.2) kan je installeren via een softwarebron (openSUSE: Packman) of via de gedownloade broncode en de opdracht ./Autoinstall.
Het verraste me dat het programma het root wachtwoord vraagt. Noem het veiligheids bewust, maar ik werk niet graag als root als het niet nodig is, ongelukjes hebben als root meestal grotere gevolgen!
Bij de eerste start wordt de configuratie van de uit te voeren backuptaak opgevraagd. GAdmin-Rsync kan meerdere backuptaken beheren, waardoor het eenvoudig wordt een backuptaak te herhalen. Je bepaalt het soort backup (lokaal naar lokaal, lokaal naar doelcomputer of broncomputer naar lokaal), de betreffende mappen en verbindingsgegevens. Hier moet je oppassen: ik vond namelijk geen manier om de verbindingsgegevens nadien nog aan te passen, waardoor je dus voor een kleine aanpassing een nieuwe backuptaak moet aanmaken wat verre van gebruiksvriendelijk is. Een ander probleem is dat het programma geen wachtwoordloze verbindingen aanvaard.
Veel franjes heeft GAdmin-Rsync niet. Zo kan je geen simulatie ("dry run") uitvoeren. Daartegenover staat dat je eenvoudig een cron taak kunt plannen om de backuptaak op een bepaald tijdstip te laten uitvoeren, vandaar het root-georiënteerde karakter van het programma; m.a.w. dit is geen programma voor gewone gebruikers maar voor systeembeheerders. Ook het Help onderdeel bewijst dit door zijn beknoptheid en een doorverwijzing naar de site http://www.gadmintools.org. Of dit programma je bevalt, hangt af van uw systeembeheerders aanleg, maar het kan zijn nut bewijzen.
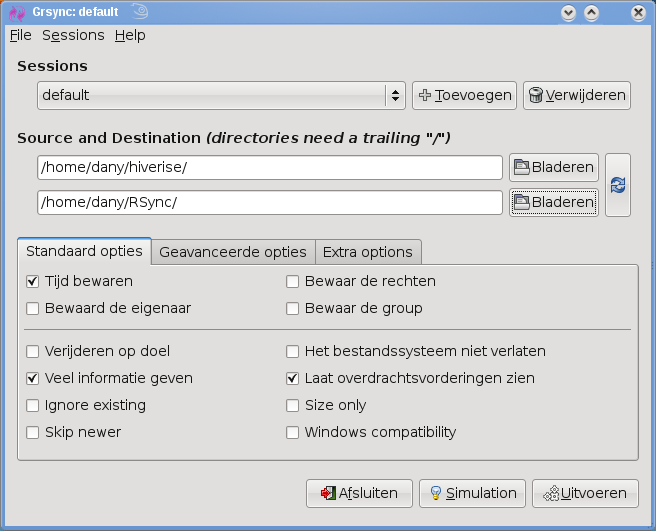 Grsync
GrsyncGrsync is een op GTK gebaseerd grafische omgeving voor rsync, dat ook in andere omgevingen dan Gnome gebruikt kan worden. De recente versie 0.6.3 heeft de volgende interessante kenmerken:
- Opslaan van sessies waardoor je backuptaken kunt herhalen.
- Simulatie van een backuptaak.
- Opdrachten voor en na de backuptaak uitvoeren.
- Bevat een terminal opdracht, grsync-batch, waarmee je Grsync sessies kunt uitvoeren, handig om in takenplanners als cron te gebruiken.
Op de webpagina van Grsync vind je enkel de broncode, die je met behulp van GTK en Autotools zelf kunt compileren. Veel softwarebronnen bieden Grsync in binaire vorm aan (openSUSE: Packman, Mandriva, Red Hat - Fedora en CentOS, enz.). Grsync is enkel een gebruikersinterface en bevat rsync zelf niet: rsync moet je dus eerst zelf installeren.
Niet alle rsync mogelijkheden zijn aanwezig, maar voor de meeste gebruikers, zullen de aanwezige mogelijkheden ruim volstaan. Als je meer wilt, gebruik je het tabblad Geavanceerde opties, waar je elke benodigde optie via argumenten kunt toevoegen. Let goed op de schrijfwijze, bij typfouten zal Grsync niet klagen, maar tijdens het uitvoeren zal rsync zelf wel een foutbericht tonen. Daarnaast is het een bruikbaar en stabiel programma, waarschijnlijk de beste van de hier beschreven grafische rsync omgevingen.
QSync en TKsync
QSync is een op QT gebaseerde gebruikersinterface. De ontwikkeling ervan lijkt gestopt bij versie 0.3 van december 2005.
Dit hulpmiddel kan ik niet aanraden omdat het zijn eigen rsync versie gebruikt.
M.a.w. QSync gebruikt een oude niet up to date ingebouwde rsync versie en niet de recente rsync versie van uw distributie.
Daarbij gaf de auteur in 2003 toe dat de synchronisatie nog niet werkt zoals het hoort, en aangezien er sindsdien geen aanpassingen meer verschenen, moeten we aannemen dat de problemen nog niet opgelost zijn.
Als je op zoek gaat naar grafische omgevingen voor rsync kom je misscien terecht bij het TKsync project, de laatste versie (0.2.1) verscheen in 2004. De project pagina op het internet is tegenwoordig leeg. We kunnen er dus vanuit gaan dat dit project dood en begraven is. Mocht je toch nog een installatiepakket vinden, kan je dit maar beter negeren.
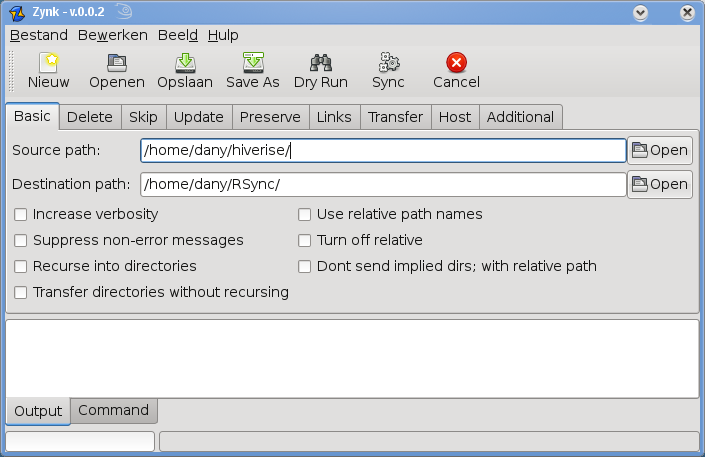 Zynk
Zynk
Hoewel de ontwikkeling van Zynk pas begonnen is, lijkt het een veelbelovend project.
Je moet dus nog wat rekening houden met enkele (voorlopige) beperkingen.
Daarnaast zijn er pakketten voor verschillende distributies (openSUSE: Packman).
Zynk is een GTK+ applicatie die zowel in Gnome als KDE werkt (de afbeelding toont Zynk in de KDE omgeving).
Versie 0.0.2 van Zynk verscheen in februari 2009 en de auteur zegt zelf dat het programma momenteel nog honderden fouten (bugs) bevat! Sommige onderdelen werken nog niet zoals verwacht! ENKEL OP EIGEN RISICO TE GEBRUIKEN! Volgens de auteur is pas 10 procent van het programma klaar, toch lijkt dit eerder een waarschuwing dan de werkelijkheid.
Zynk ondersteunt de meeste (waarschijnlijk zelfs alle) rsync mogelijkheden. Zync gebruikt rsync, die je dus ook moet installeren. Onderaan het venster tonen tabbladen de uitvoer en opdrachtregel van rsync.
Na het testen van het programma bleek duidelijk dat Zynk nog niet af is. Maar in tegenstelling tot QSync, wordt er volop aan Zynk gewerkt en is de kans groot dat het programma in de nabije toekomst bruikbaar wordt.
Conclusie
Het rsync hulpmiddel is een standaard opdracht voor de terminal waarmee je moet leren werken om op een eenvoudige, veilige en snelle manier mappen te synchroniseren. Voor wie liever met een grafische gebruikersinterface werkt, is vandaag Grsync waarschijnlijk de beste keuze, QSync is hopeloos verouderd en zowel aan GAdmin-Rsync en Zynk wordt nog volop gewerkt.
Stap voor stap gaan we een simpel webgalerie script schrijven. Dit script maakt van foto's of afbeeldingen een html pagina die je op het internet kunt publiceren.
Het script moet in staat zijn afbeeldingen te verkleinen. Om dit te realiseren gebruiken we ImageMagick, een pakket dat in alle distributies aanwezig is. M.a.w. zorg dat het pakket imagemagick op uw computer geïnstalleerd is. Als alternatief kan je GraphicsMagick, een variant op ImageMagick, gebruiken. De basis opdrachten zijn toch dezelfde.
Om het script te testen heb je een map nodig met afbeeldingen. Werk met een kopie van de originele afbeeldingen, want het script zal de afbeeldingen aanpassen. Indien je niet met kopies werkt, zullen de de originele afbeeldingen overschreven worden. Je bent gewaarschuwd. Het script plaatsen we eveneens in de map met de gekopieerde afbeeldingen.
Twee handige ImageMagick opdrachten zijn convert en mogrify.
Het enige verschil tussen de twee is dat convert een nieuw bestand aanmaakt, terwijl mogrify een bestaand bestand aanpast.
M.a.w. mogrify verandert de originele afbeelding - vandaar dat je best met kopies van originele afbeeldingen werkt, terwijl convert de aangepaste afbeelding in een ander bestand opslaat en daardoor het origineel ongemoeid laat.
mogrify -scale 640 img001.jpgconvert -scale 120 img001.jpg mini-img001.jpg#! /bin/sh for afbeelding in *.jpg ; do echo $afbeelding convert -scale 120 "$afbeelding" mini-"$afbeelding" mogrify -scale 640 "$afbeelding" donefor start de lus. afbeelding is de lus plaatshouder (variabele): bij elke doorloop bevat deze plaatshouder de bestandsnaam van een afbeelding. Om de bestandnaam van een afbeelding binnen de lus in een opdracht te gebruiken, plaats je er een dollar teken voor: $afbeelding.
in *.jpg bepaalt welke bestanden één voor één in de plaatshouder afbeelding terecht komen. Uiteindelijk sluit ; de lijst met waarden voor de plaatshouder afbeelding af en kan de lus starten.
De echo opdracht toont welke afbeelding wordt verwerkt. echo plaats namelijk alles wat erop volgt op het scherm, m.a.w. echo $afbeelding plaatst de bestandsnaam van de afbeelding die door convert en mogrify verwerkt zal worden op het scherm.
Sla het script op in de map met de (gekopieerde) afbeeldingen als webgalerie.sh. Test het script in de terminal vanuit de map met de (gekopieerde) afbeeldingen met de opdracht:sh webgalerie.shecho "<h1>Mijn Afbeeldingen</h1>" > index.html>> voegt opdracht-uitvoer toe aan een bestand, zodat je elke afbeelding met de volgende regel aan het HTML bestand kunt toevoegen:
echo "<a href="$afbeelding"><img src="mini-$afbeelding"></a>" >> index.htmlHet script wordt dan:
#! /bin/sh echo "<html> <head> <title> Mijn Afbeeldingen</title></head><body> " > index.html echo "<h1>Mijn Afbeeldingen</h1>" >> index.html for afbeelding in *.jpg ; do echo $afbeelding convert -scale 120 "$afbeelding" mini-"$afbeelding" mogrify -scale 640 "$afbeelding" echo "<a href=\"$afbeelding\"><img src=\"mini-$afbeelding\"></a>" >> index.html done echo "</body></html>" >>index.htmlOm het HTML bestand volgens de regels op te bouwen plaatst de eerste echo opdracht de noodzakelijke beginonderdelen en de laatste echo de noodzakelijke afsluitende onderdelen voor de HTML pagina. Daarnaast merk je dat de meeste plaatshouders tussen aanhalingstekens staan, deze zijn noodzakelijk om bestandsnamen met spaties correct te verwerken. Om deze aanhalingstekens in het HTML bestand te kunnen plaatsen, gebruiken we \". Het \ teken zorgt ervoor dat het erop volgend teken letterlijk wordt gebruikt, hier in ons geval wordt dus een aanhalingsteken aan het HTML bestand toegevoegd.
Terwijl een aantal opdrachten, zoals cd in bash ingebouwd zijn; maken de belangrijkste opdrachten deel uit van de coreutils, een GNU pakket met meer dan honderd opdrachten.
Sommige opdrachten zoals ls, mv en cat zijn bekend.
Andere opdrachten zijn minder bekend, meestal omdat er andere modernere programma's bestaan die gelijkaardige opdrachten kunnen uitvoeren.
Deze minder bekende opdrachten weerspiegelen dikwijls de geschiedenis van het werken met een computer waarbij bijna alles in een Bourne of Bash terminal werd afgewerkt, liever dan te wachten tot programma's als emacs of vi opgestart waren, die in de goede oude tijd bekend stonden als geheugenvreters en nu bliksemsnel zijn (je kan ze zelfs op een mobiele telefoon gebruiken).
Tijd om even wat aandacht aan enkele van deze handige opdrachten te besteden.
tac
Eén van de sleutelopdrachten is cat, kort voor concatenate, die je kan gebruiken om de inhoud van een bestand aan een ander bestand toe te voegen of om een bestand of een groep bestanden op het scherm te tonen.
echo een > 1.txt
echo twee > 2.txt
cat 1.txt 2.txt > 3.txt # voegt bestand 1.txt samen met 2.txt tot het nieuwe bestand 3.txt.
cat 3.txt # Toont het bestand 3.txt op het scherm.tac 3.txt > 4.txt # 4.txt is een omgekeerde kopie van 3.txt.tee
Vaak gebruik je de uitvoer van een opdracht als invoer voor een andere opdracht:
ps -e | grep bashps -e | grep bash > bash-processen.txtps -e | grep bash | tee bash-processen.txt # toont de uitvoer op het scherm en plaatst deze in een bestand.pr
Alles wat je printers aanbiedt, wordt vandaag de dag afgedrukt. Toch wil je een bestand op een bepaalde manier opmaken voor je het naar de printer stuurt. Een voorbeeld, bij het bespreken van een bepaalt bestand op een vergadering, wil je dit elke week op dezelfde manier presenteren. De pr opdracht maakt een tekst bestand klaar voor de printer. Daarbij kan je bijvoorbeeld het pagina- en kolomformaat bepalen.
pr +10 -h"Xorg log" -l25 /var/log/Xorg.0.log | lpr -# 5stat
ls -l geeft veel informatie over een bestand.
Nog meer informatie kan je opvragen met de opdracht stat:
stat /var/log/Xorg.0.log
File: '/var/log/Xorg.0.log'
Size: 16195 Blocks: 32 IO Block: 4096 normaal bestand
Device: 806h/2054d Inode: 1368200 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2009-07-16 20:23:02.000000000 +0200
Modify: 2009-07-16 19:46:25.000000000 +0200
Change: 2009-07-16 19:46:25.000000000 +0200yes
yes typt een tekenreeks gevolgt door Return en herhaalt dit tot het onderbroken wordt. Dit klinkt stom, toch heeft het een paar toepassingen. Eerst en vooral als je van een interactieve opdracht een niet-interactieve opdracht wilt maken. Er zijn namelijk opdrachten die bij het uitvoeren vragen of je wel zeker bent. Een voorbeeld:
yes n | rm -i *.txtexpand
Bij het schrijven van een script heb je tabs gebruikt om in te springen. Maar moderne programmeurs gebruiken vandaag de dag spaties in plaats van tabs. Geen probleem, de expand opdracht converteert tabs naar spaties, in het voorbeeld worden twee spaties voor elke tab gebruikt:
expand -2 ouderwets.sh > modern.shunexpand gebruiken.
split
split splits een bestand in meerdere bestanden. Een voorbeeld:
split -l 20 /var/log/Xorg.0.log deeluniq
Soms bestaat een bestand uit een opsomming van items en wil je alle dubbele regels verwijderen, of wil je de items groeperen en hun voorkomen tellen. Om alle dubbele regels te verwijderen gebruik je:
cat 1.txt 1.txt | uniqcat 1.txt 1.txt | uniq -cwc
wc telt het aantal regels, woorden en letters in een bestand. Standaard worden ze alle drie weergegeven:
wc /var/log/Xorg.0.logwc -l /var/log/Xorg.0.logwc -w /var/log/Xorg.0.logshred
De opdracht rm koppelt een bestand los van het bestandssysteem zodat de ruimte ingenomen door het bestand terug beschikbaar wordt voor andere bestanden.
Verwijderde bestanden kunnen met wat geluk en doorzettingsvermogen teruggehaald worden.
De opdracht shred overschrijft het bestand meermaals, waardoor het bijna onmogelijk wordt het terug te halen.
Dit kan handig zijn voor het verwijderen van financiëële gegevens zoals uw kredietkaart details.
shred -u kredietkaart.txtshred /dev/sda6rm).
In het geval van de partitie, moet deze na het herhaaldelijk overschrijven blijven bestaan.
Er zijn wat complicaties. Een complexe RAID configuratie kan dit als een hardware fout interpreteren en de gegevens herstellen.
Bij het synchroniseren van de bestanden op een server, zal shred de kopies op de server niet overschrijven.
Moderne journal bestandssystemen zoals reiserfs zullen een kopie van het bestand in de journal bewaren, m.a.w. je zult de partitie zonder journal moeten koppelen (mount) om een bestand met shred spoorloos te laten verdwijnen.
Hopelijk vond je tussen deze opdrachten een opdracht die je nog niet kende en waarvoor je een toepassing hebt.
IPTraf is een statistisch netwerk hulpprogramma voor de terminal. Het verzamelt een aantal cijfergegevens i.v.m. het aantal pakketten en bytes verzonden en ontvangen door TCP verbindingen, netwerkkaart statistieken en activiteits indicaties, uitgesplitst TCP/UDP verkeer, aantal pakketten en bytes verzonden door een LAN verbinding. IPTraf volgt en toont informatie over het IP verkeer dat uw netwerkt verwerkt. IPTraf is een terminal programma dat door het gebruik van menu's eenvoudig te bedienen en in te stellen is. IPTraf kan enkel door de root gebruiker gebruikt worden. De volgende protocollen worden ondersteund: IP, TCP, UDP, ICMP, IGMP, IGP, IGRP, OSPF, ARP, RARP en ondersteunt Loopback, Ethernet, FDDI, SLIP, Asynchroon PPP, Synchroon PPP over ISDN, ISDN met RAW IP & Cisco HDLC Encapsulation en Parallelle IP verbindingen.
Belangrijkste eigenschappen:- Toont TCP informatie zoals de toestand, aantal verzonden en ontvangen pakketten en bytes, ICMP details, OSPF pakket types.
- Algemene en gedetailleerde statistieken per aansuiting i.v.m. IP, TCP, UDP, ICMP, geen-IP en ander IP pakket verkeer, IP controlesommen, aansluitingsactiviteit, grootte van de pakketten.
- Een TCP en UDP monitor toont het aantal inkomende en uitgaande pakketten voor populaire TCP en UDP poorten
- Een LAN module die actieve hosts kan opsporen en statistieken van hun activiteit kan tonen
- Toont met behulp van TCP, UDP en andere protocol filters het netwerkverkeer die je interessant vindt
- Mogelijkheid tot loggen (bijhouden van de verzamelde informatie)
- Ondersteunt Ethernet, FDDI, ISDN, SLIP, PPP en loopback aansluitingen
- Maakt gebruik van de in de kernel ingebouwde aansluiting om de gegevens van de netwerkkaart af te tappen (raw socket interface), waardoor een groot aantal netwerkkaarten ondersteund worden
In openSUSE 11.1 kan je IPTraffic met YaST (Software installeren) installeren.
IPTraf vind je dan terug in /usr/sbin/.
Om het hulpprogramma te starten, voer je in een terminal de opdracht sudo /usr/sbin/iptraf uit.
Druk op een willekeurige toets om het menu te laten verschijnen.
Je ziet een lijst met mogelijke monitor opdrachten waaronder het realtime (live) volgen van het IP verkeer, algemene en gedetailleerde aansluitingsoverzichten, een overzicht van de storingen en een LAN station monitor.
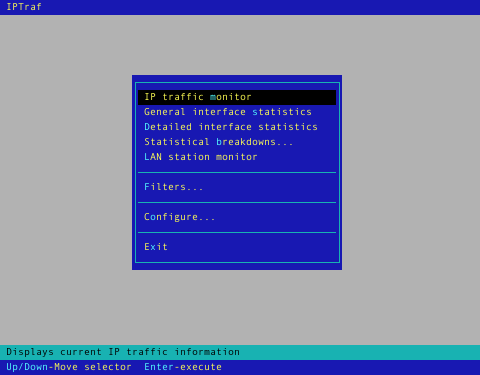
Stel IPTraf in met de opdracht Configure in het menu. Handig lijkt mij om Reverse DNS Lookup en TCP Service Names te activeren, waardoor je met computer- en poortnamen werkt i.p.v de IP adressen en poortnummers. Met de pijltoetsen selecteer je een optie en met Return schakel je de geselecteerde optie om. Naar aloude traditie staan de toetsenbord opdrachten onderaan het terminalscherm. Eenmaal de instellingen klaar zijn, verlaat (exit) je ze en kies je een monitor opdracht.
De IP Traffic Monitor toont live het IP verkeer op de geselecteerde aansluitingen.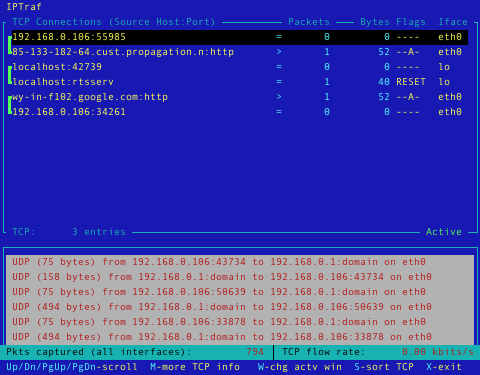
De General en Detailed interface statistics tonen het aantal pakketten, onderverdeeld in IP en ander verkeer, totaal aantal bytes/bits in en uit de gekozen aansluiting.
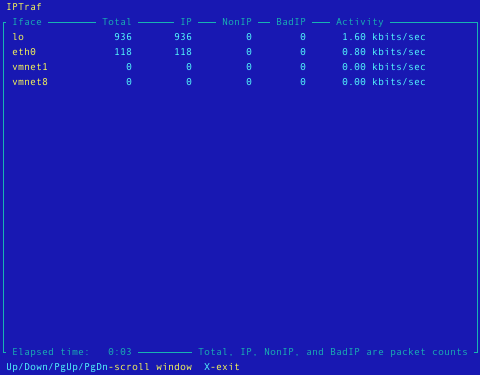
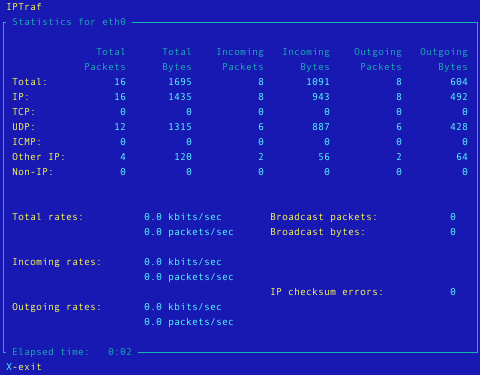
Het uitsplitsen van de pakketten gebaseerd op grootte of op de gebruikte TCP of UDP poort kan via de de opdracht Statistical breakdowns.
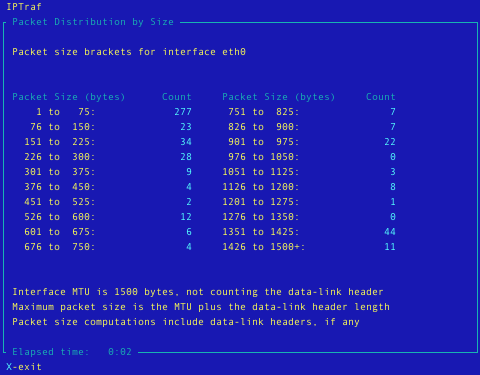
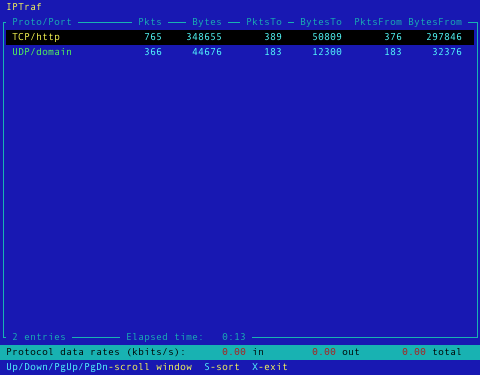
De LAN station monitor toont de ethernet harware adressen van de gebruikte bron en doel apparaten, de uitgaande en inkomende IP pakketten, in- en uitgaande Bytes/bits, e.d.m..
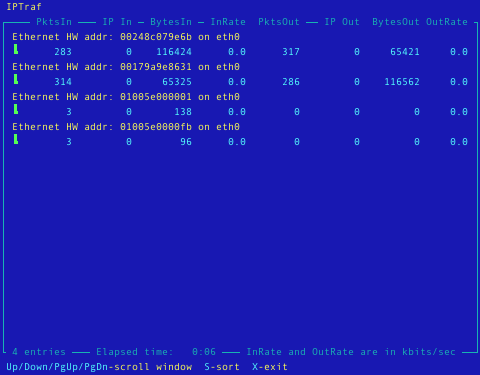
IPTraf is een mooi uitgevoerde efficiente netwerk monitor voor de terminal. Klik hier om de projectpagina te bezoeken.
pngcrush is een hulpmiddel om PNG (Portable Network graphic) bestanden te optimaliseren. pngcrush is een opdracht die je in de terminal of scripts kunt gebruiken om PNG afbeeldingen beter te comprimeren (lees kleiner te maken), wat nuttig kan zijn om bijvoorbeeld webpagina's sneller te maken. Afhankelijk van het programma die de PNG bestanden aangemaakt heeft, kan pngcrush de bestandsgrootte met een paar tot 40% en meer verkleinen (zonder verlies aan kwaliteit). Het verkleint de grootte van de PNG IDAT datastream door verschillende compressieniveau's van de PNG filter methoden uit te proberen. Het kan ook gebruikt worden om ondergeschikte stukken te verwijderen, of bepaalde stukken, waaronder qAMA, tRNS, iCCP en teksten, toe te voegen. Daarnaast corrigeert het foutieve gamma informatie aangebracht door Photoshop 5.0 en foutieve iCCP stukken aangebracht door Photoshop 5.5.
Je kan pngcrush installeren door de softwarebron van Packman toe te voegen of door op de groene 1-click knop hiernaast te klikken. Dit start het downloaden van het YMP bestand en start de YaST-metapakketbehandelaar die op zijn beurt de noodzakelijke Packman softwarebron toevoegt en het pakket pngcrush installeert samen met alle noodzakelijke afhankelijke pakketten. En het enige wat je daarvoor moet doen is de assistent volgen.
In de eenvoudigste vorm, start je pngcrush met een bron- en een doelbestand:dany@linux-sumi:~> pngcrush Test.png Resultaat.png
| pngcrush 1.6.19
| Copyright (C) 1998-2002,2006-2009 Glenn Randers-Pehrson
| Copyright (C) 2005 Greg Roelofs
| This is a free, open-source program. Permission is irrevocably
| granted to everyone to use this version of pngcrush without
| payment of any fee.
| Executable name is pngcrush
| It was built with libpng version 1.2.37, and is
| running with libpng version 1.2.37 - June 4, 2009
| Copyright (C) 1998-2004,2006-2009 Glenn Randers-Pehrson,
| Copyright (C) 1996, 1997 Andreas Dilger,
| Copyright (C) 1995, Guy Eric Schalnat, Group 42 Inc.,
| and zlib version 1.2.3.3, Copyright (C) 1998-2002 (or later),
| Jean-loup Gailly and Mark Adler.
| It was compiled with gcc version 4.3.2 [gcc-4_3-branch revision 141291].
Recompressing Test.png
Total length of data found in IDAT chunks = 47516
unknown chunk handling done.
IDAT length with method 1 (fm 0 zl 4 zs 0) = 43381
IDAT length with method 2 (fm 1 zl 4 zs 0) = 50393
IDAT length with method 3 (fm 5 zl 4 zs 1) = 50460
IDAT length with method 4 (fm 0 zl 9 zs 1) = 44419
IDAT length with method 7 (fm 0 zl 9 zs 0) = 40429
Best pngcrush method = 7 (fm 0 zl 9 zs 0) for Resultaat.png
(14.91% IDAT reduction)
(14.97% filesize reduction)
CPU time used = 0.180 seconds (decoding 0.030,
encoding 0.150, other 0.000 seconds)
Als je meerdere PNG afbeeldingen in één keer wilt optimaliseren, specifieer je te optimaliseren bestanden (gebruik van jokers kan) en geef je de extensie (-e) voor de geoptimaliseerde bestanden op en/of een doelmap met het -d argument.
Een voorbeeld: met de volgende opdracht optimaliseer ik al mijn PNG bestanden in de huidige map en plaats deze in de map Afbeeldingen:
dany@linux-sumi:~> pngcrush -d Afbeeldingen -e .optimaal.png *.png
In bovenstaand voorbeeld bepaald -d Afbeeldingen de doelmap en -e .optimaal.png de aan de bestandsnaam toegevoegde extensie van alle geoptimaliseerde PNG bestanden.
dany@linux-sumi:~> pngcrush
| pngcrush 1.6.19
| Copyright (C) 1998-2002,2006-2009 Glenn Randers-Pehrson
| Copyright (C) 2005 Greg Roelofs
| This is a free, open-source program. Permission is irrevocably
| granted to everyone to use this version of pngcrush without
| payment of any fee.
| Executable name is pngcrush
| It was built with libpng version 1.2.37, and is
| running with libpng version 1.2.37 - June 4, 2009
| Copyright (C) 1998-2004,2006-2009 Glenn Randers-Pehrson,
| Copyright (C) 1996, 1997 Andreas Dilger,
| Copyright (C) 1995, Guy Eric Schalnat, Group 42 Inc.,
| and zlib version 1.2.3.3, Copyright (C) 1998-2002 (or later),
| Jean-loup Gailly and Mark Adler.
| It was compiled with gcc version 4.3.2 [gcc-4_3-branch revision 141291].
If you have modified this source, you may insert additional notices
immediately after this sentence.
Copyright (C) 1998-2002,2006-2009 Glenn Randers-Pehrson
Copyright (C) 2005 Greg Roelofs
DISCLAIMER: The pngcrush computer program is supplied "AS IS".
The Author disclaims all warranties, expressed or implied, including,
without limitation, the warranties of merchantability and of fitness
for any purpose. The Author assumes no liability for direct, indirect,
incidental, special, exemplary, or consequential damages, which may
result from the use of the computer program, even if advised of the
possibility of such damage. There is no warranty against interference
with your enjoyment of the computer program or against infringement.
There is no warranty that my efforts or the computer program will
fulfill any of your particular purposes or needs. This computer
program is provided with all faults, and the entire risk of satisfactory
quality, performance, accuracy, and effort is with the user.
LICENSE: Permission is hereby irrevocably granted to everyone to use,
copy, modify, and distribute this computer program, or portions hereof,
purpose, without payment of any fee, subject to the following
restrictions:
1. The origin of this binary or source code must not be misrepresented.
2. Altered versions must be plainly marked as such and must not be
misrepresented as being the original binary or source.
3. The Copyright notice, disclaimer, and license may not be removed
or altered from any source, binary, or altered source distribution.
usage: pngcrush [options] infile.png outfile.png
pngcrush -e ext [other options] files.png ...
pngcrush -d dir [other options] files.png ...
options:
-already already_crushed_size [e.g., 8192]
-bit_depth depth (bit_depth to use in output file)
-brute (use brute-force: try 126 different methods [11-136])
-c color_type of output file [0, 2, 4, or 6]
-d directory_name (where output files will go)
-double_gamma (used for fixing gamma in PhotoShop 5.0/5.02 files)
-e extension (used for creating output filename)
-f user_filter [0-5]
-fix (fix otherwise fatal conditions such as bad CRCs)
-force (write a new output file even if larger than input)
-g gamma (float or fixed*100000, e.g., 0.45455 or 45455)
-huffman (use only zlib strategy 2, Huffman-only)
-itxt b[efore_IDAT]|a[fter_IDAT] "keyword"
-keep chunk_name
-l zlib_compression_level [0-9]
-loco ("loco crush" truecolor PNGs)
-m method [0 through 200]
-max maximum_IDAT_size [default 8192]
-mng (write a new MNG, do not crush embedded PNGs)
-newtimestamp
-nofilecheck (do not check for infile.png == outfile.png)
-oldtimestamp
-n (no save; doesn't do compression or write output PNG)
-plte_len n (truncate PLTE)
-q (quiet)
-reduce (do lossless color-type or bit-depth reduction)
-rem chunkname (or "alla" or "allb")
-replace_gamma gamma (float or fixed*100000) even if it is present.
-res dpi
-rle (use only zlib strategy 3, RLE-only)
-save (keep all copy-unsafe chunks)
-srgb [0, 1, 2, or 3]
-ster [0 or 1]
-text b[efore_IDAT]|a[fter_IDAT] "keyword" "text"
-trns_array n trns[0] trns[1] .. trns[n-1]
-trns index red green blue gray
-v (display more detailed information)
-version (display the pngcrush version)
-w compression_window_size [32, 16, 8, 4, 2, 1, 512]
-z zlib_strategy [0, 1, 2, or 3]
-zmem zlib_compression_mem_level [1-9, default 9]
-zitxt b[efore_IDAT]|a[fter_IDAT] "keyword"
-ztxt b[efore_IDAT]|a[fter_IDAT] "keyword" "text"
-h (help and legal notices)
-p (pause)
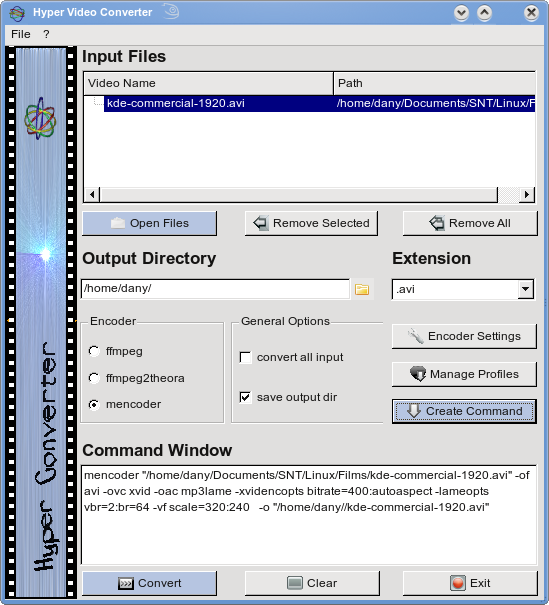 Soms moeten we uit noodzaak tijd doden. Bijvoorbeeld in de wachtzaal van de huisarts.
In zo'n wachtzaal liggen meestal wel wat boekjes, maar deze dateren uit lang vervlogen tijden en/of zijn geen leesvoer voor een linuxfanaat.
Vandaar dat ik in 2006 een GP2X-F100, een op linux werkende draagbare spelcomputer aankocht.
Daar zo'n toestel maar een opslagcapaciteit van 64MB heeft, kocht ik er prompt een SD geheugenkaart van 2GB bij.
Tot nu toe nam ik het toestel mee, als ik vermoede dat ik wat tijd zou moeten doden.
Tijdens het wachten speel ik dan wat eenvoudige spellen zoals sudoku, patience, frozen bubble, tetris, edm.
Onlangs na zowat drie jaar, besefte ik dat ik de spelcomputer ook als videospeler kan inzetten en in de wachtzaal rustig naar een filmpje kan kijken.
Het toestel blijft op 2 AA batterijen drie en een half uur (twee films) werken, heeft een kleurenscherm met een resolutie van 320x240 en de software ondersteund het afspelen van video's in het DivX 3/4/5, XviD (MPEG4) formaat met geluid in het MP3 of Vorbis formaat in bestanden van het AVI of OGM type.
De 2GB opslagruimte lijkt op het eerste zicht een probleem. Maar door de geringe schermgrootte 3,5" en resolutie kunnen we de film eerst omzetten (encoderen) naar deze resolutie.
Dit heeft twee voordelen: ten eerste zal de kwaliteit beter zijn (gespecialiseerde programma's passen een film beter aan een bepaalde resolutie aan dan de videospelers) en de bestandsgrootte zal sterk afnemen.
Soms moeten we uit noodzaak tijd doden. Bijvoorbeeld in de wachtzaal van de huisarts.
In zo'n wachtzaal liggen meestal wel wat boekjes, maar deze dateren uit lang vervlogen tijden en/of zijn geen leesvoer voor een linuxfanaat.
Vandaar dat ik in 2006 een GP2X-F100, een op linux werkende draagbare spelcomputer aankocht.
Daar zo'n toestel maar een opslagcapaciteit van 64MB heeft, kocht ik er prompt een SD geheugenkaart van 2GB bij.
Tot nu toe nam ik het toestel mee, als ik vermoede dat ik wat tijd zou moeten doden.
Tijdens het wachten speel ik dan wat eenvoudige spellen zoals sudoku, patience, frozen bubble, tetris, edm.
Onlangs na zowat drie jaar, besefte ik dat ik de spelcomputer ook als videospeler kan inzetten en in de wachtzaal rustig naar een filmpje kan kijken.
Het toestel blijft op 2 AA batterijen drie en een half uur (twee films) werken, heeft een kleurenscherm met een resolutie van 320x240 en de software ondersteund het afspelen van video's in het DivX 3/4/5, XviD (MPEG4) formaat met geluid in het MP3 of Vorbis formaat in bestanden van het AVI of OGM type.
De 2GB opslagruimte lijkt op het eerste zicht een probleem. Maar door de geringe schermgrootte 3,5" en resolutie kunnen we de film eerst omzetten (encoderen) naar deze resolutie.
Dit heeft twee voordelen: ten eerste zal de kwaliteit beter zijn (gespecialiseerde programma's passen een film beter aan een bepaalde resolutie aan dan de videospelers) en de bestandsgrootte zal sterk afnemen.
Om video's te encoderen heb je gespecialiseerde programma's zoals ffmpeg, ffmpeg2theora of mencoder nodig. Deze programma's zijn zo gespecialiseerd dat ze geen grafische omgeving gebruiken. Als leek in de videowereld leek me dit een moeilijk karwei te worden. Ik ging dus op zoek naar een frontend (GUI), met andere woorden een programma waarmee ik de gespecialiseerde programma's kan besturen zonder me te verdiepen in de complexe wereld van encoders en hun werking. Daarbij kwam ik terecht bij Avidemux, WinFF en het hier besproken Hyper Video Converter. Ik koos de laatste omdat deze genoeg functies heeft om mijn doel te bereiken en gebruiksvriendelijk genoeg is zodat ik ermee kon werken.
Installeer de pakketten ffmpeg (afkomstig van de softwarebron Packman of VLC, ffmpeg2theora (Packman) en mplayer (Packman)(bevat mencoder). Hyper Video Converter moet je downloaden van de site zelf. Daar worden verschillende versies aangeboden: één voor Gnome gebruikers (gtk2-versie) en één voor KDE4 gebruikers (qt4-versie). Ikzelf ben een openSUSE 11.1 KDE4 gebruiker en koos wijselijk om de qt4 versie voor suse te downloaden (hypervc-0.4.1-qt4-suse.tar.bz2) te downloaden. Na het downloaden staat het bestand in de Desktop-map.- Start Konqueror en ga naar uw Persoonlijke map.
- Splits het venster met het menu Venster > Venster verticaal opsplitsen.
- Open in het linker deelvenster de map Desktop en klik op het gedownloade bestand (hypervc-0.4.1-qt4-suse.tar.bz2).
- Sleep de map hypervc-suse naar het rechter deelvenster en kopieer de map naar dit deelvenster.
- Start een terminal en voer de opdracht
sudo rpm -Uvh hypervc-suse/hypervc-0.4.1-linux-2.6-intel.rpmuit. - Daarna kopieer je het verborgen configuratiebestand naar uw persoonlijke map met de opdracht (let op de punt achteraan:
dany@linux-qgyf:~>cp hypervc-suse/.hyperconf .
Nu je toch in de terminal werkt, kan je het programma starten met de opdracht hypervc.
64 bits gebruikers (de meesten onder ons) krijgen de foutmelding hypervc: error while loading shared libraries: libQtCore.so.4: cannot open shared object file: No such file or directory, wat wijst op het feit dat Hyper Video Converter een 32-bits programma is.
Na de installatie van het pakket libqt4-32bit via YaST (gevonden door te zoeken naar libQtCore waarbij de optie RPM "Provides" ingeschakeld werd).
Bij de volgende poging om hypervc te starten krijg je op een 64-bits systeem nogmaals een gelijkaardige melding, deze keer in verband met de gedeelde bibliotheek libQtGui.so.4.
Na de installatie van het pakket libqt4-x11-32bit is ook dit van de baan.
Na het starten van Hyper Video Converter (via K Menu of terminal) kan je in het venster bovenaan de om te zetten films toevoegen met de knop Open Files. Daaronder kies je met de bladerknop van de Output Directory de map waarin de omgezette films moeten worden opgeslagen. Daaronder kies je het programma waarmee je de omzetting wilt uitvoeren. Hier kies je voor het programma die het formaat dat je wenst te gebruiken ondersteunt en/of de beste resultaten oplevert (experimenteel te bepalen). In het voorbeeld kies ik voor mencoder. Mencoder ondersteunt zoals ffmpeg veel verschillende formaten waarbij we voorgeconfigureerde instellingen kunnen kiezen door rechts te klikken op de knop Manage Profiles. De mensen die wat meer willen, kunnen klikken op de knop Encoder Settings om de configuratie manueel op te geven.
In het dialoogvenster Mencoder Settings leg je het videoformaat (Video Format (Container), avi in het voorbeeld), de gebruikte filmcodering (Codec library, in het voorbeeld xvid (libxvid)) vast. De filmcodering bepaalt de verdere video instellingen (tabblad Video Options).
Op het tabblad Audio Options leg je de gebruikte geluidscodering (Codec Library, in het voorbeeld mp3 (lame)) vast. Deze keuze bepaalt de overige geluidsinstellingen. Bij de MP3 opties (lameopts) activeer ik de optie Bitrate waarmee ik de geluidskwaliteit en bestandsgrootte kan beinvloeden. Hoe hoger de bitrate, hoe beter de geluidskwaliteit, maar ook hoe groter het uiteindelijke bestand wordt (in het voorbeeld sluit ik een compromis door 64 te kiezen).
Op het tabblad Filter kan je de grootte van de film vastleggen (in het voorbeeld gebruik ik custom om in het tekstvak eronder de schermafmeting 320:240 in te geven). De fimp wordt door het opgeven van de afmetingen niet vervormd, Je bepaalt dus alleen de afmetingen waarin de film moet passen, niet de afmetingen van de film zelf.
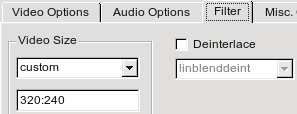
Op het tabblad Misc. Options kan je de beeldsnelheid (Framerate), geluidsnauwkeurigheid (Audio Samplerate) instellen en opties zoals FourCC en 2-pass Encoding waaraan ik in het voorbeeld niets verander.
Na het instellen van de Mencoder Settings kan je met de knop Save as profile deze instellingen opslaan, zodat je ze later nogmaals kunt gebruiken (in het voorbeeld heb ik de instellingen opgeslagen in het profiel GP2X). Na het opslaan van de instellingen kan je ze met de knop OK bevestigen.
Met de knop Create Command in het hoofdvenster van Hyper Video Converter maak je van alle bovenstaande instellingen een opdracht in het Command Window. Deze opdracht kan je uitvoeren door op de knop Convert te klikken. Deze opdracht kan je eveneens selecteren en kopiëren om deze daarna in een terminal te plakken en uit te voeren. Het voordeel van de omweg naar een opdracht is de flexibiliteit. Mensen die meer instellingen willen manipuleren dan degene die aangeboden worden door Hyper Video Converter kunnen deze zo manueel aan de opdracht in het Command Window toevoegen.
Bij het klikken op de Convert knop merk je dat Hyper Video Converter onze opdracht niet kan uitvoeren (FAILED!). Maar waarom? Wel het antwoord vinden we als we op de knop View Program Output klikken. In het venster met de uitvoer van de opdracht staat bijna helemaal onderaan (schuif de tekst naar beneden met de muiswiel of de pijltoets naar beneden) de reden: xvid: you must specify one or a valid combination of 'bitrate', 'pass', 'fixed_quant' settings. Met andere woorden we hebben in de Encoder Settings vergeten een Video Bitrate (hoe hoger de bitrate, hoe beter de beeldkwaliteit, maar ook hoe groter het bestand wordt en hoe krachtiger de afspeelapparatuur moet zijn) of enkele andere opties in te stellen. In het voorbeeld kies ik weer voor een compromis en stel ik de Video Bitrate in op 400. Na het bevestigen van de aanpassing en het omzetten naar een opdracht verloopt de omzetting zonder problemen.
Na de omzetting van de voorbeeldfilm (originele bestandsgrootte 78,9 MB, filmformaat: 1920:1072) zit de film in een bestand met een grootte van 3,3 MB en heeft de film een formaat 320:240. Een film op DVD (origine bestandsgrootte 4,1 GB, filmformaat: 720:576) zet je zo op een moderne computer in een half uur om in een filmbestand met een grootte van 514 MB en een formaat van 320:240.
Daarna rest ons alleen nog de omgezette filmbestanden naar de GP2X speler te kopiëren. De GP2X speler kan je via de USB 1.1 verbinding met de computer verbinden, maar bij het kopiëren van de voor de GP2X grote bestanden liep deze vast. Een duidelijk stabielere en snellere methode is de SD geheugenkaart uit de GP2X speler te halen en deze in de kaartlezer van de computer te plaatsen. Vergeet niet voor het verwijderen van de SD geheugenkaart deze eerst veilig te verwijderen. Dit kan zelfs na het kopiëren van een groot bestand wat tijd in beslag nemen. Gebruik je geen Veilig verwijderen, dan kan het bestand nog niet helemaal op de SD geheugenkaart staan en/of kan in het ergste geval het bestandssysteem op de geheugenkaart verminkt worden waardoor herformateren noodzakelijk is.
Installeer Flash Player en activeer JavaScript om deze film af te spelen.
Internet en Video
Je kan Hyper Video Converter ook inzetten als je video's door een flash speler op het internet wilt laten afspelen. Deze keer maak ik gebruik van de ffmpeg Encoder. Flash films hebben als Extension .flv. De Encoder Settings voor flash films kan je instellen zoals op de afbeelding.
Zoals je ziet op de afbeelding wordt gebruik gemaakt van MP3 voor het geluid, dit is enkel mogelijk als het pakket lame geïnstalleerd is. Bij het schrijven van deze howto, bleek het lame pakket dat aangeboden werd op de VLC softwarebron niet te werken (foumelding), terwijl de versie van Packman zonder problemen werkte. De originele film heeft een bestandsgrootte van 4,7 MB met een formaat van 720x576. Na de omzetting paste de film in een bestand van 1,2 MB en heeft de film een 320x256 formaat (m.a.w. 2,25 maal kleiner dan het origineel).
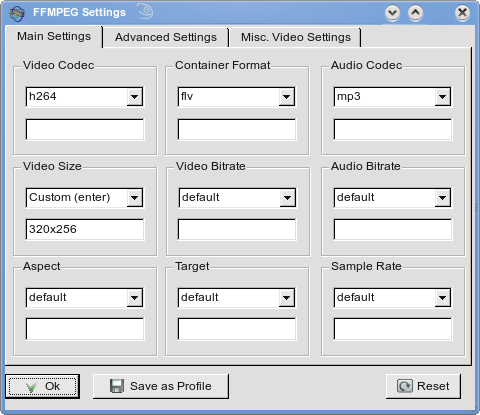
Onlangs kreeg openSUSE 11.1 via een update een nieuwe kernel. Zoals gebruikelijk bij de update van een nieuwe kernel moet de VMware Player zijn kernel-modules opnieuw aanmaken (samenwerking tussen VMware Player en besturingssysteem optimaliseren). Daarvoor wordt sedert VMware Player 2.5 een grafische interface gebruikt. Deze blijkt echter niet meer in staat te zijn de nieuwe kernel-modules voor kernel 2.6.27.23 aan te maken.
Dan maar terugvallen op de oude vertrouwde methode via een script.
Het aanmaken van de kernel-modules kan met het volgende script:
#!/bin/bash cd ~ rm -rf vmware-modules mkdir vmware-modules cd vmware-modules find /usr/lib/vmware/modules/source -name "*.tar" -exec tar xf '{}' \; mkdir -p /lib/modules/`uname -r`/misc rm -f /lib/modules/`uname -r`/misc/{vmblock.ko,vmci.ko,vmmon.ko,vmnet.ko,vsock.ko} cd vmblock-only; make; cd ..; cp -p vmblock.o /lib/modules/`uname -r`/misc/vmblock.ko cd vmci-only; make; cd ..; cp -p vmci.o /lib/modules/`uname -r`/misc/vmci.ko cd vmmon-only; make; cd ..; cp -p vmmon.o /lib/modules/`uname -r`/misc/vmmon.ko cd vmnet-only; make; cd ..; cp -p vmnet.o /lib/modules/`uname -r`/misc/vmnet.ko #cd vmppuser-only; make; cd ..; cp -p vmppuser.o /lib/modules/`uname -r`/misc/vmppuser.ko cd vsock-only; make; cd ..; cp -p vsock.o /lib/modules/`uname -r`/misc/vsock.ko depmod -a service vmware restart #If a new install, remove the not_configured tag or the error will keep coming back rm -f /etc/vmware/not_configured
Een totaalbeeld. Om de nieuwe VMware Player op openSUSE 11.1 te installeren onderneem je de volgende stappen:
- Haal de voor uw systeem geschikte rpm af (VMware Download). Het afgehaalde RPM bestand eindigd op .x86_64.rpm voor een 64-bits systeem en op .i386.rpm voor een 32-bits systeem.
- Start een terminal.
- Installeer het afgehaalde pakket met de opdracht
sudo rpm -Uvh Documents/Linux/VMware/VMware-Player-2.5.*.rpm. - Om VMware Player te configureren en zich aan te passen aan het systeem heeft het extra onderdelen nodig.
Deze kan je installeren met de opdracht
sudo zypper install gcc kernel-source make. - Start de VMware Player (K menu > Programma's > Systeem > Meer programma's > VMware Player). Volg de instructies van de VMware Player Assistent.
Voor kernel 2.6.27.23 voer je de volgende extra stappen uit:- Start een editor (vb: Kwrite).
- Kopieer het bovenstaande script.
- Plak het script in de editor.
- Sla het script op als vmware-modules.sh.
- Voer in de terminal de opdracht
sudo sh vmware-modules.shuit.
- Om virtuele computers aan te maken installeer je vmx-manager met de opdracht
sudo zypper install vmx-manager. De VMX-manager kan je starten via K menu > Programma's > Hulpmiddelen > Bureaublad > Virtuele-machine-beheer. De aangemaakte virtuele computers komen terecht in de map ~/vmware/ en kunnen alleen gestart worden via de VMware Player zelf (dus niet vanuit de VMX-manager). - Na de installatie van VMware kan je VMware opstarten, maar bij het opstarten van een virtuele machine krijg je de foutmelding
Could not open /dev/vmmon. Dit kan je verhelpen door voor het opstarten van VMware de virtuele apparaten te herinitialiseren.- Grafische oplossing
- Maak in de Desktop-map een Nieuwe Link to application... aan (rechtermuisklik) met de volgende kenmerken:
- Tabblad Algemeen als Pictogram bij Toepassingen het pictogram vmware-player of vmware-workstation
- Tabblad Algemeen als naam in het tekstvak VMware Player
- Tabblad Toepassing als Commando
su -c "/etc/init.d/vmware restart"; vmplayer - Tabblad Toepassing bij de Geavanceerde opties
In een terminal uitvoeren.
vmplayerdoorvmware. - Terminal oplossing
echo '[Desktop Entry]' > /home/$USER/Desktop/VMware\ Player.desktop
echo 'Exec=su -c "/etc/init.d/vmware restart"; vmplayer' >> /home/$USER/Desktop/VMware\ Player.desktop
echo 'Icon=vmware-workstation' >> /home/$USER/Desktop/VMware\ Player.desktop
echo 'StartupNotify=true' >> /home/$USER/Desktop/VMware\ Player.desktop
echo 'Terminal=true' >> /home/$USER/Desktop/VMware\ Player.desktop
echo 'Type=Application' >> /home/$USER/Desktop/VMware\ Player.desktop
echo 'X-DBUS-StartupType=none' >> /home/$USER/Desktop/VMware\ Player.desktop
echo 'X-KDE-SubstituteUID=false' >> /home/$USER/Desktop/VMware\ Player.desktop
echo 'X-SuSE-translate=true' >> /home/$USER/Desktop/VMware\ Player.desktop
- De bibliotheken nodig om VMware te configureren, kunnen nu verwijderd worden (mogen ook blijven staan, zie opmerking).
Daarbij zal meer dan 260 MB ruimte op de harde schijf vrijkomen.
Dit kan met met de opdracht
sudo zypper remove gcc kernel-source make.
De VMware Player kan je van de computer verwijderen door de volgende stappen uit te voeren:
- Start een terminal.
- Start de opdracht
sudo vmware-uninstall. - Na de succesvolle uninstall moet je het VMware Player pakket verwijderen met de opdracht
sudo rpm --erase vmware-player.
Opmerking
Na een opwaardering (update) van de kernel via het internet, moet je de configuratie opnieuw uitvoeren. Dit is noodzakelijk om de VMware Player de kans te geven zich aan de nieuwe kernel aan te passen.
Naast het zoeken van bestanden in een mapstructuur, kan je find diverse taken laten uitvoeren. De hier beschreven voorbeelden zijn zowel te gebruiken door beginners als door gevorderden.
Voor we beginnen, maak je met de volgende opdrachten lege bestanden in uw Persoonlijke map aan om de find opdrachten straks te testen.
dany@linux-sumi:~>touch MijnbashProgramma.shdany@linux-sumi:~>touch mijncprogramma.cdany@linux-sumi:~>touch MijnCProgramma.cdany@linux-sumi:~>touch Programma.cdany@linux-sumi:~>mkdir backupdany@linux-sumi:~>cd backupdany@linux-sumi:~/backup>touch MijnbashProgramma.shdany@linux-sumi:~/backup>touch mijncprogramma.cdany@linux-sumi:~/backup>touch MijnCProgramma.cdany@linux-sumi:~/backup>touch Programma.cdany@linux-sumi:~/backup>cd ..
1 Zoeken op bestandsnamen
Dit is een basistaak van de find opdracht.
Het voorbeeld vindt alle bestanden met de naam MijnCProgramma.c in de huidige map en alle onderliggende mappen.
dany@linux-sumi:~> find -name "MijnCProgramma.c"
./backup/MijnCProgramma.c
./MijnCProgramma.c
2 Hoofdletterongevoelig zoeken op bestandsnamen
Het voorbeeld vindt alle bestanden met de naam MijnCProgramma.c in de huidige map en alle onderliggende mappen zonder rekening te houden met het hoofdlettergebruik.
dany@linux-sumi:~> find -iname "MijnCProgramma.c"
./backup/mijncprogramma.c
./backup/MijnCProgramma.c
./mijncprogramma.c
./MijnCProgramma.c
3 Beperk het zoeken tot bepaalde submappen
Zoek het passwd bestand in alle submappen beginnend vanaf de basismap (/).
De redirection 2> zorgt ervoor dat de foutmeldingen (Toegang geweigerd) in het niets (/dev/null) verdwijnen.
dany@linux-sumi:~> find / -name passwd 2> /dev/null
/var/run/nscd/passwd
/etc/passwd
/etc/pam.d/passwd
/etc/default/passwd
/usr/bin/passwd
Zoek het passwd bestand in de basismap (/) en één niveau lager (m.a.w. basismap - niveau 1 en één submap lager - niveau 2).
dany@linux-sumi:~> find / -name passwd -maxdepth 2 2> /dev/null
/etc/passwd
Zoek het passwd bestand in de basismap (/) en twee niveaus lager.
dany@linux-sumi:~> find / -name passwd -maxdepth 3 2> /dev/null
/etc/passwd
/etc/pam.d/passwd
/etc/default/passwd
/usr/bin/passwd
Zoek het passwd bestand in de submapniveau's twee tot en met vier.
dany@linux-sumi:~> find / -name passwd -mindepth 3 -maxdepth 5 2> /dev/null
/var/run/nscd/passwd
/etc/pam.d/passwd
/etc/default/passwd
/usr/bin/passwd
4 Opdrachten uitvoeren op de gevonden bestanden
In het voorbeeld wordt de md5sum berekend van alle bestanden met de naam MijnCProgramma.c (zonder hoofdlettergevoeligheid).
{} wordt daarbij telkens vervangen door de gevonden bestanden.
dany@linux-sumi:~> find -iname "MijnCProgramma.c" -exec md5sum {} \;
d41d8cd98f00b204e9800998ecf8427e ./backup/mijncprogramma.c
d41d8cd98f00b204e9800998ecf8427e ./backup/MijnCProgramma.c
d41d8cd98f00b204e9800998ecf8427e ./mijncprogramma.c
d41d8cd98f00b204e9800998ecf8427e ./MijnCProgramma.c
5 De zoekresultaten omkeren
Toont de bestanden en mappen in de map backup waarvan de naam niet overeenkomt met MijnCProgramma.c.
dany@linux-sumi:~> find backup -not -iname "MijnCProgramma.c"
backup
backup/MijnbashProgramma.sh
backup/Programma.c
6 Zoeken op inode Number
Elk bestand heeft een uniek inode number waarmee een bestand geïdentificeerd kan worden.
Maak twee bestanden met gelijkaardige namen, één bestandnaam heeft een spatie achteraan.
dany@linux-sumi:~>touch "spatie-test"dany@linux-sumi:~>touch "spatie-test "dany@linux-sumi:~>ls -1 spatie*spatie-test spatie-test
Via de uitvoer van de ls opdracht kan je de twee bestanden niet onderscheiden.
Met het i argument kan je het inode number van het bestand zien, en dit is voor de twee bestanden anders.
dany@linux-sumi:~> ls -1i spatie*
6466590 spatie-test
6466605 spatie-test
Je kan het inode number met de find opdracht meegeven. In het voorbeeld hernoemt find een bestand met een bepaald inode number.
dany@linux-sumi:~>find -inum 6466605 -exec mv {} spatie-hernoemt \;dany@linux-sumi:~>ls -1i spatie*6466605 spatie-hernoemt 6466590 spatie-test
Je kan deze techniek gebruiken om bewerkingen uit te voeren op bestanden met slecht gekozen namen.
Als voorbeeld een bestand met in de naam een speciaal teken zoals een vraagteken.
Als je de opdracht rm bestand?.txt uitvoert, zullen de bestanden bestand1.txt en bestand2.txt ook verwijderd worden.
Volg de volgende stappen om enkel het bestand bestand?.txt te verwijderen.
dany@linux-sumi:~>touch bestand1.txt bestand2.txt bestand?.txtdany@linux-sumi:~>ls bestand*bestand1.txt bestand2.txt bestand?.txt
Toon de inode numbers van de bestanden.
dany@linux-sumi:~> ls -1i bestand*
6464158 bestand1.txt
6465456 bestand2.txt
6466455 bestand?.txt
Gebruik het inode number om het bestand met het vraagteken in de naam te verwijderen.
dany@linux-sumi:~>find -inum 6466455 -exec rm {} \;dany@linux-sumi:~>ls bestand*bestand1.txt bestand2.txt
7 Zoeken op toegangsrechten
De volgende bewerkingen zijn mogelijk:
- Zoeken naar bestanden met specifieke toegangsrechten
- Zoeken naar bestanden met bepaalde toegangsrechten.
- Zoeken via numerieke / symbolische toegangsrechten.
We maken de volgende bestanden met verschillende toegangsrechten.
dany@linux-sumi:~>touch alles_voor_iedereen iedereen_lezen niets_voor_iedereen gewoon_bestand groep_lezen alleen_groep_lezendany@linux-sumi:~>chmod 777 alles_voor_iedereendany@linux-sumi:~>chmod 040 alleen_groep_lezendany@linux-sumi:~>chmod 600 gewoon_bestanddany@linux-sumi:~>chmod 640 groep_lezendany@linux-sumi:~>chmod 000 niets_voor_iedereendany@linux-sumi:~>ls -l *_*----r----- 1 dany users 0 jun 6 20:26 alleen_groep_lezen -rwxrwxrwx 1 dany users 0 jun 6 20:26 alles_voor_iedereen -rw------- 1 dany users 0 jun 6 20:26 gewoon_bestand -rw-r----- 1 dany users 0 jun 6 20:26 groep_lezen -rw-r--r-- 1 dany users 0 jun 6 20:26 iedereen_lezen ---------- 1 dany users 0 jun 6 20:26 niets_voor_iedereen
Zoek bestanden met leesrechten voor de groep.
dany@linux-sumi:~> find -maxdepth 1 -perm -g=r -type f -name "*_*" -exec ls -l {} \;
-rwxrwxrwx 1 dany users 0 jun 6 20:26 ./alles_voor_iedereen
-rw-r----- 1 dany users 0 jun 6 20:26 ./groep_lezen
-rw-r--r-- 1 dany users 0 jun 6 20:26 ./iedereen_lezen
----r----- 1 dany users 0 jun 6 20:26 ./alleen_groep_lezen
Zoek bestanden die alleen leesrechten heeft voor de groep.
dany@linux-sumi:~> find -maxdepth 1 -perm g=r -type f -name "*_*" -exec ls -l {} \;
----r----- 1 dany users 0 jun 6 20:26 ./alleen_groep_lezen
Zoek bestanden die alleen leesrechten hebben (numeriek).
dany@linux-sumi:~> find -maxdepth 1 -perm 040 -type f -name "*_*" -exec ls -l {} \;
----r----- 1 dany users 0 jun 6 20:26 ./alleen_groep_lezen
8 Zoeken naar lege bestanden (grootte 0)
De meeste lege bestanden zijn blokkeer-bestanden (lock-files) en variabelen die door programma's werden aangemaakt.
dany@linux-sumi:~> find -empty
De lege bestanden in de huidige map zonder de submappen te doorzoeken.
dany@linux-sumi:~> find -maxdepth 1 -empty
Zoek enkel de niet verborgen lege bestanden in de huidige map.
dany@linux-sumi:~> find -maxdepth 1 -empty -not -name ".*"
9 De vijf grootste bestanden zoeken
De volgende opdracht toont de vijf grootste bestanden in de huidige map en zijn submappen.
Deze opdracht kan afhankelijk van het aantal te doorzoeken bestanden wat tijd in beslag nemen.
dany@linux-sumi:~> find . -type f -exec ls -s {} \; | sort -n -r | head -5
10 De vijf kleinste bestanden zoeken
Daarvoor gebruiken we dezelfde techniek als voor het opzoeken van de vijf grootste bestanden, de sortering keren we echter om.
dany@linux-sumi:~> find . -type f -exec ls -s {} \; | sort -n | head -5
Waarschijnlijk toont de vorige opdracht enkel bestanden met een grootte van nul bytes (lege bestanden).
Met de volgende opdracht zie je de vijf kleinste bestanden die niet leeg zijn.
dany@linux-sumi:~> find . -not -empty -type f -exec ls -s {} \; | sort -n | head -5
11 Zoek op type
Zoek naar socket bestanden (communicatie-verbinding tussen processen, programma's).
dany@linux-sumi:~> find . -type s
Zoeken naar mappen.
dany@linux-sumi:~> find . -type d
Zoeken naar gewone bestanden.
dany@linux-sumi:~> find . -type f
Zoeken naar verborgen bestanden.
dany@linux-sumi:~> find . -type f -name ".*"
Zoeken naar verborgen mappen.
dany@linux-sumi:~> find . -type d -name ".*"
12 Bestanden zoeken door de wijzigingstijd te vergelijken met een ander bestand
Toont de bestanden die gewijzigd werden na een bepaald bestand.
De volgende opdracht toont alle bestanden die aangemaakt/aangepast werden na het bestand groep_lezen.
dany@linux-sumi:~>touch gewoon_bestand alles_voor_iedereen alleen_groep_lezendany@linux-sumi:~>ls -ltr *_*---------- 1 dany users 0 jun 6 20:26 niets_voor_iedereen -rw-r--r-- 1 dany users 0 jun 6 20:26 iedereen_lezen -rw-r----- 1 dany users 0 jun 6 20:26 groep_lezen -rw------- 1 dany users 0 jun 11 18:22 gewoon_bestand -rwxrwxrwx 1 dany users 0 jun 11 18:22 alles_voor_iedereen ----r----- 1 dany users 0 jun 11 18:22 alleen_groep_lezen public_html: totaal 0 dany@linux-sumi:~>find -maxdepth 1 -newer groep_lezen -name "*_*"./alles_voor_iedereen ./gewoon_bestand ./.bash_history ./alleen_groep_lezen
13 Zoeken op grootte
Met het -size argument kan je bestanden op grootte zoeken.
Grotere bestanden zoeken:
dany@linux-sumi:~> find ~ -size +100M
Kleinere bestanden zoeken:
dany@linux-sumi:~> find ~ -size -100M
Bestanden met een bepaalde grootte zoeken:
dany@linux-sumi:~> find ~ -size 100M
- betekent dus kleiner dan de opgegeven grootte, + betekent groter dan de opgegeven grootte en geen symbool betekent exact de opgegeven grootte.
14 Een veel gebruikte find opdracht een schuilnaam (alias) geven
Veel gebruikte opdrachten kan je een korte gemakkelijk te onthouden alias geven. De betreffende opdracht kan je dan uitvoeren door de alias te gebruiken.
De bestanden a.out regelmatig verwijderen.
dany@linux-sumi:~>alias rmao="find . -iname a.out -exec rm {} \;"dany@linux-sumi:~>rmao
15 Grote archiefbestanden verwijderen
De volgende opdracht verwijdert *.zip bestanden die groter zijn dan 100M.
dany@linux-sumi:~> find . -type f -name *.zip -size +100M -exec rm -i {} \;
Verwijder alle *.tar bestanden die groter zijn dan 2G door gebruik te maken van de alias rm2g (Remove 2G).
dany@linux-sumi:~>alias rm2g="find . -type f -name *.tar -size +2G -exec rm -i {} \;"dany@linux-sumi:~>rm2g
netcat is het zwitsers zakmes voor TCP/IP. De man pagina formuleert het zo: netcat is a simple unix utility which reads and writes data across network connections, using TCP or UDP protocol. It is designed to be a reliable "back-end" tool that can be used directly or easily driven by other programs and scripts. At the same time, it is a feature-rich network debugging and exploration tool, since it can create almost any kind of connection you would need and has several interesting built-in capabilities.
1 Voorwoord
netcat bestaat in verschillende vormen: netcat en nc zijn de meest voorkomende vormen (in openSUSE 11.1 is netcat standaard geïnstalleerd, nc installeer je via het pakket netcat-openbsd).
We gebruiken voor de voorbeelden twee computersystemen:
server1.voorbeeld.com: IP adres 192.168.0.106
server2.voorbeeld.com: IP adres 192.168.0.172
netcat moet op de systemen geïnstalleerd zijn - je kan dit controleren met
which netcat
Om meer te weten te komen over netcat, raadpleeg je zijn man pagina
man netcat
Sommige van deze voorbeelden kunnen hun werk maar uitvoeren nadat je de gebruikte poorten in de firewall opent.
2 Een bestand van het ene naar het andere systeem kopiëren
Laten we het bestand ISPConfig-2.2.27.tar.gz kopiëren van server1 naar server2. Start daarvoor op server1 de opdracht
netcat -lp 1234 > ISPConfig-2.2.27.tar.gz
1234 is daarbij een ongebruikte poort - die je door elke andere waarde mag vervangen. server2 wacht nu op het bestand ISPConfig-2.2.27.tar.gz op poort 1234.
Op server2 start je de opdracht
netcat -w 1 server2.voorbeeld.com 1234 < ISPConfig-2.2.27.tar.gz
om de bestandsuitwisseling te starten.
3 Harde schijven en partities klonen
Je kan netcat gebruiken om harde schijven/partities via het netwerk te klonen.
In het voorbeeld, gaan we /dev/sda van server1 klonen naar server2.
Daarbij mag de doelpartitie niet gekoppeld zijn, m.a.w. bij het klonen van de systeempartitie, moet de doelcomputer (server2) via een hulpsysteem of LiveCD zoals Knoppix opgestart worden.
Merk daarbij op dat het IP adres van het doelsysteem daarbij kan veranderen.
Het IP adres kan je opvragen met de opdracht
/sbin/ifconfig
In het voorbeeld gebruikt server2 het IP adres 192.168.0.12 i.p.v. 192.168.0.172.
Op server2 start je de volgende opdracht
netcat -l -p 1234 | dd of=/dev/sda
Nadien start je op server1 de opdracht
dd if=/dev/sda | netcat 192.168.0.12 1234
om het klooonproces te starten. Dit kan wat tijd in beslag nemen en is afhankelijk van grootte van de harde schijf of partitie.
4 Poorten aftasten
Op server1 kan je geopende poorten op server2 scannen met de opdracht
netcat -v -w 1 server2.voorbeeld.com -z 1-1024
(met 1-1024 scan je de poort nummers 1 tot en met 1024).
Het lokale systeem kan je scannen met de opdracht
netcat -v -w 1 localhost -z 1-1024
5 HTTP verbinding nabootsen
Start het luisteren met de opdracht
netcat -lp 3333
start daarna de browser en surf naar http://localhost:3333
In de terminal verschijnen de berichten die de browser normaal naar de webserver stuurt.
Daarna kan je deze berichten naar een webserver op het internet sturen met de opdracht
netcat www.google.be 80
en de al dan niet aangepaste berichten in de terminal te plakken (moet eindigen met een lege regel, m.a.w. twee returns).
Waardoor de webserver op uw aanvraag zal reageren en de reactie zichtbaar wordt in de terminal.
6 Chatten
Je kan chatten door op server1 te luisteren met de opdracht
netcat -vlp 3333
De verbinding wordt op server2 opgebouwd met de opdracht
netcat 192.168.0.106 3333
Na het opbouwen van de verbinding krijgt de gebruiker op server1 een bericht en kan het chatten starten.
Jawel de tijd om uw belastingsaangifte in te vullen is terug aangebroken. Nu de papieren versie een stuk complexer is geworden, kijken we allemaal uit naar de vooringevulde versie op het Internet. Volgens de officiële site (Tax-on-Web) hebben we daarvoor een token of eID nodig. De token is een kaart met nummers die je moet aanvragen en die je dan kunt gebruiken om u op de site van Tax on Web aan te melden. De eID is uw elektronische identiteitskaart waarmee je je eveneens op de site van Tax on Web kunt aanmelden. Naast uw elektronische identiteitskaart heeft u een gepaste kaartlezer nodig en uw pincode. Ik gebruik de officiële kaartlezer (ACR38U) die je via een USB poort op uw computer kunt aansluiten. Op de site eID staat de installatieprocedure en jawel ook voor Linux. Na het uitvoeren van de daar beschreven installatie-procedure, startte ik de software. Oops een foutmelding i.v.m. een niet gevonden library. Deze software is duidelijk enkel bruikbaar op 32 bits systemen. Daarna ging ik ten rade bij Novell zelf (EID-belgium) met de volgende installatie procedure:
- Installeer via K menu > Computer > Software installeren de pakketten 'eID-belgium' en 'eIDconfig-belgium'.
- Installeer via Software installeren het pakket met het PCSC stuurprogramma (driver) voor uw kaartlezer. Voorbeeld: voor een ACR 38 kaartlezer, installeer je het pakket 'pcsc-acr38'.
- Activeer via K menu > Computer > YaST > Systeem > Systeemservices (Runlevel) de 'pcscd' dienst.
- Start de eID Configuratie software via K menu > Programma's > Beveiliging > Activeer toepassingen voor eID Systeem of voer de opdracht
eidconfig-belgiumuit.
 Na het starten van de eID Configuratie software, kan je op het tabblad Toepassingen bepalen met welke software je de elektronische identificatie wilt gebruiken.
Voor Tax on Web moet je enkel Firefox aanvinken (indien gewenst kan je eID ook gebruiken met openOffice.org, Evolution en Thunderbird).
Na het starten van de eID Configuratie software, kan je op het tabblad Toepassingen bepalen met welke software je de elektronische identificatie wilt gebruiken.
Voor Tax on Web moet je enkel Firefox aanvinken (indien gewenst kan je eID ook gebruiken met openOffice.org, Evolution en Thunderbird).
Op het tabblad Kaart Informatie kan je na het plaatsen en uitlezen van de electronische identiteitskaart de Naam, Voornaam, Geboortedatum en Nationaal nummer van de houder aflezen. Nog meer informatie krijg je bij het klikken op de knop Toon alle informatie. Dit extra dialoogvenster heeft een tabblad Certificaten waarop je informatie vindt over de certificaten die je nodig hebt om je aan te melden op bijvoorbeeld de Tax-on-Web site, met o.a. de geldigheidsperiode van de certificaten. Klik op de knop Sluiten om dit extra dialoogvenster te sluiten.
Op het laatste tabblad Wijzig PIN kan je de PIN code van uw kaart wijzigen. Enkel en alleen als je de huidige PIN code van de kaart kent.
Nu Firefox nog op de hoogte brengen van de eID certificaten. Op de site van eID vond ik bij de FAQ een onderdeel over de middleware (eID software) en Firefox 3. Het lijkt alsof eID niet ontwikkeld werd voor moderne systemen en software (moeite met 64 bits systemen, recente browsers). Maar steeds is een kant en klare oplossing te vinden, en deze keer op de site van eID zelf in de vorm van een PDF document voor Firefox 3 gebruikers (weliswaar de Windows versie). Ziehier een vertaling van de werkwijze voor Firefox 3 onder Linux:
- Surf naar https://www.mijndossier.rrn.fgov.be/. Je krijgt een Waarschuwing i.v.m. het gebruik van een ongeldig beveiligingscertificaat. Sluit het dialoogvenster met de waarschuwing.
- Klik in Firefox op de koppeling (hyperlink) Of u kunt een uitzondering toevoegen....
- Klik op de knop Uitzondering toevoegen....
- Klik in het dialoogvenster Beveiligingsuitzondering toevoegen op de knop Certificaat ophalen.
- Klik op de knop Beveiligingsuitzondering bevestigen. Je krijgt nu een internetpagina met als titel The page requires a client certificate.
- Sluit Firefox.
- Start Firefox terug op en surf naar https://www.mijndossier.rrn.fgov.be/.
- Bevestig het dialoogvenster Gebruikersidentificatieverzoek.
- Typ uw PIN code in en klik op de knop OK.
- Klik op de taal naar keuze en bekijk uw online dossier.
Nu enkel nog surfen naar Tax-on-Web, u aanmelden met eID en uw belastingsaangifte online invullen en doorsturen. Klaar.
We hebben allemaal wel eens een fout gemaakt tijdens een configuratie waarbij we in de tijd tot voor de fout terug wilden keren. Nu je de ultieme configuratie waar je zolang aan werkte, hebt bereikt. Hoe kan je dan die configuratie na een systeem- of harde schijf crash herstellen? We zoeken daarvoor een methode om alle gegevens en persoonlijke instellingen veilig te stellen. Na het herstellen van de crash, is het herstellen (restore) met behulp van een Live CD, een terminal en enkele commando's zo voorbij.
Zorg er eerst voor dat de backup niet op dezelfde schijf als het Linux systeem terecht komt. Een uitwendige USB schijf is voor het ogenblik een betaalbaar medium om uw backup op te plaatsen, een alternatief is een tweede harde schijf in de computer.
De eenvoudigste methode is het gebruik van een eenvoudig tar commando zoals:
tar cvpzf backup.tgz --exclude=/proc --exclude=/lost+found --exclude=/backup.tgz --exclude=/mnt --exclude=/media --exclude=/sys /
Met behulp van argumenten kan tar bestanden en mappen in de backup opnemen of uitsluiten.
Met het exclude argument sluiten we zo systeemmappen of individuele bestanden die niet in de backup thuishoren uit.
De hier uitgesloten mappen worden na de terugzet procedure heraangemaakt (zie verder).
De hierboven aangemaakte backup terugzetten, kan eenvoudig door als root naar de hoofdmap / te gaan en het volgende commando uit te voeren:
tar xvpfz backup.tgz -C /
WAARSCHUWING!! Dit zal elk bestand op uw partitie overschrijven met het overeenkomstig bestand in het backup archief!
Om de herstelling te vervolledigen moeten de met exclude argumenten uit de backup uitgesloten mappen aangemaakt worden met:
mkdir proc
mkdir lost+found
mkdir mnt
mkdir media
mkdir sysDankzij het gebruik van het tar commando om de backup aan te maken, heb je de mogelijkheid om elk bestand of map uit de backup te halen.
Als je bijvoorbeeld een beschadigd of verkeerd geconfigureerd fstab bestand wilt herstellen, kan dat met het commando:
tar -zxvpf backup.tgz /etc/fstab
Vanuit de basismap / wordt het bestand /etc/fstab zelfs op de originele plaats teruggezet. Een veiliger oplossing is om het te herstellen bestand in uw persoonlijke map (of een andere map) te plaatsen, en het daarna te vergelijken, te verplaatsen of aan te passen op de oorspronkelijke locatie. Dit werkt eveneens voor complete mappen.
Wanneer je het beu wordt steeds opnieuw het wachtwoord voor sudo in te typen, en je wilt niet (of je hebt onvoldoende rechten) om NOPASSWD in het sudoers bestand op te nemen, kan je de volgende procedure volgen om de sudo wachtwoord tijdslimiet telkens te resetten en zo het hertypen van het wachtwoord te omzeilen:
- Maak het script $HOME/bin/sudo-passwd-reset.sh
#!/bin/bash while [ true ]; do sudo -u root /bin/true > /dev/null 2> /dev/null sleep 60 done
- Start sudo om de wachtwoord tijdslimiet te initialiseren:
sudo -u root /bin/true
Password: ********* - Start het script $HOME/bin/sudo-passwd-reset.sh in de achtergrond:
$HOME/bin/sudo-passwd-reset.sh &
Nu kan je sudo zonder wachtwoord gebruiken, ook na een lange periode waarin je sudo niet gebruikte.
Opmerking: er zijn zeker en vast veiligheidsgevolgen bij het gebruik van deze methode; dit is echter eveneens het geval bij het gebruik van NOPASSWD in het sudoers bestand.
De volgende methoden kunnen gebruikt worden om het root wachtwoord waarvan je het wachtwoord niet kent toch aan te passen.
Als je GRUB als bootmanager gebruikt, selecteer je het besturingssysteem dat je wilt starten en voeg je 1 toe aan de opstartopties. Indien je geen opstartopties kunt opgeven, probeer je GRUB's bewerken opdracht (de letter e van edit, in de grafisch mode van GRUB moet je eerst Esc drukken). De 1 laat de kernel starten in de single-user modus.
Het systeem start nu naar een root prompt. Op dit moment kan je met de opdracht passwd het root wachtwoord aanpassen.
Indien dit niet lukt (openSUSE 11.1) start je de computer met een rescue CD of een installatie CD waarmee je op de opdrachtregel kunt werken.
Eenmaal op de opdrachtregel, koppel je de systeempartitie indien deze nog niet gekoppeld is:
mkdir /mnt/systeem
mount /dev/sda1 /mnt/systeem
mount --bind /dev /mnt/systeem/devsudo.
Voer nu een chroot uit en pas het root wachtwoord aan:
chroot /mnt/systeem /bin/bash
passwd rootMet de opdrachtregel in Linux werken is plezant. In het begin kan het je wat overdonderen, zeker in tijden waarin GUI's (Graphic User Interface) de norm schijnen te zijn. Met CLI (Command Line Interface) kunnen we echter veel taken sneller uitvoeren als we de mogelijkheden van bepaalde opdrachten kennen.
Een zeer flexibele opdracht is find. Met find kan je niet enkel zoeken op basis van bestandsnamen, maar ook op GID (Group ID) en UID (User ID), tijd en datum en bestandstypen.
Ziehier enkele voorbeelden met de find opdracht:
- Deze opdracht vindt alle bestanden in de map /home waarvan de naam eindigd op .doc die in de laatste 24 uren gewijzigd werden:
find /home -name *.doc -mtime 0
- Deze vindt dezelfde bestanden uitgezonderd de mappen, en verwijderd deze met behulp van de -exec optie (fantastisch voor het beheer van het schijfgebruik, maar zorg eerst voor een RESERVEKOPIE!):
find /home -name *.doc -type f -mtime 0 -exec rm {} \;
- Zoeken naar bestanden van een bepaalde gebruiker (UID):
find /tmp -user dany
find /tmp -uid 1000
- of groep (GID):
find /home/dany -gid 100
- Zoeken naar bestanden en mappen met bepaalde rechten:
find . -perm -777
Op basis van deze voorbeelden kan je zelf een opdracht samenstellen om te vinden wat je zoekt.
- Wanneer je een volledig bestandssysteem van de ene computer naar een andere moet kopiëren, bijvoorbeeld bij de aanschaf van een nieuwe computer, ga je als volgt tewerk:
- Start beide computers met een Linux live CD (bijvoorbeeld Knoppix), en zorg ervoor dat ze via een netwerk met elkaar verbonden zijn.
- Op de bron computer koppel (mount) je de te kopiëren partitie en start je het overzetten met netcat en tar:
cd /mnt/sda1
tar -czpsf - . | nc -l 3333 - Op de doelcomputer koppel je de partitie waarop de kopie moet komen en start je het ontvangen van de gegevens met:
cd /mnt/sda1
nc 192.168.10.101 3333 | tar -xzpsf -
Het nc (netcat) commando wordt voor allerlei soorten TCP verbindingen tussen twee computers gebruikt. tar wordt gebruikt om op de broncomputer de bestanden te verzamelen en te comprimeren en op de doelcomputer terug uit te pakken. Om het verloop van de overdracht te volgen kan je het commando pv (process viewer) met de optie -b tussen het tar en nc commando plaatsen.
Onlangs had ik een script nodig om de inhoud van twee bestanden te verwerken. Het verwerken vond telkens plaats op een regel van het eerste bestand en op een regel van het tweede bestand. Dit lijkt eenvoudig, maar is het niet als je niet op de hoogte bent van de uitgebreide omleidings (redirection) mogelijkheden van bash.
In het voorbeeld gaan we een regel van twee bestanden lezen, deze voegen we samen tot één regel en voeren dit gecombineerde resultaat in een enkele regel uit naar het scherm. Ons voorbeeld beperkt zich tot twee invoerbestanden. Het script voert geen foutcontrole uit en gaat ervan uit dat de twee bestanden evenveel regels bevatten.
Onze bestanden, bestand1 en bestand2 zijn:
dany@linux-sumi:~>cat bestand1b1 1 b1 2 b1 3 b1 4 dany@linux-sumi:~>cat bestand2b2 1 b2 2 b2 3 b2 4
Uw eerste poging zou er als volgt kunnen uitzien:
#!/bin/bash while read b1 <$1 do read b2 <$2 echo $b1 $b2 done
Bij het uitvoeren merkt je dat dit niet het gewenste resultaat oplevert:
dany@linux-sumi:~> sh niet-goed.sh bestand1 bestand2
b1 1 b2 1
b1 1 b2 1
b1 1 b2 1
b1 1 b2 1
...
Ctrl-C
Elke omleiding start telkens opnieuw: de lus heropent telkens het bestand en leest steeds opnieuw de eerste regel waardoor je in een eindeloze lus terecht komt.
De volgende poging bestaat uit het volledig inlezen van beide bestanden en daarna de in het geheugen gebufferde gegevens te verwerken:
#!/bin/bash i=0 while read regel do b1[$i]="$regel" let i++ done <$1 i=0 while read regel do b2[$i]="$regel" let i++ done <$2 i=0 while [[ "${b1[$i]}" ]] do echo ${b1[$i]} ${b2[$i]} let i++ done
En dit werkt:
dany@linux-sumi:~> sh goed.sh bestand1 bestand2
b1 1 b2 1
b1 2 b2 2
b1 3 b2 3
b1 4 b2 4
Deze methode werkt bij dit eenvoudige voorbeeld prachtig, maar wordt bij complexere taken moeilijk en omslachtig in het gebruik.
Een tweede oplossing krijg je door gebruik te maken van de geavanceerde omleiding:
#!/bin/bash while read b1 <&7 do read b2 <&8 echo $b1 $b2 done \ 7<$1 \ 8<$2
In deze versie specifiëren we op het einde van de lus meerdere invoeromleidingen door gebruik te maken van de volledige algemene vorm van de bash invoeromleiding: [n]<word.
Indien geen [n] voorkomt is deze standaard 0, wat normaal toetsenbordinvoer (stdin) is.
Door echter een klein geheel getal voor de omleiding te plaatsen, kunnen we meerdere invoer bestanden aan het commando doorgeven, in dit geval is het commando de while lus:
... done \ 7<$1 \ 8<$2
Dit zorgt ervoor dat de while lus met de voor lezen geopende bestandsbeschrijving (file descriptor) 7 voor het eerste bestand en de voor lezen geopende bestandsbeschrijving 8 voor het tweede bestand doorlopen wordt. Normaal gebruik je getallen groter dan 2, want 0-2 worden gebruikt voor standaard invoer (stdin), standaard uitvoer (stdout) en foutmeldingen (stderr).
Om de lees commando's te laten werken, gebruiken we een andere vorm van de bash omleiding, deze waarmee bash de mogelijkheid heeft de bestandsbeschrijving te dupliceren (zoals in C de functie dup2()). Het dupliceren van bestandsbeschrijvingen laat toe twee bestandsbeschrijvingen te laten verwijzen naar één open bestand. Daar lezen normaal gebeurt vanuit stdin (standaard invoer) en niet van de bestandsbeschrijving 7 of 8 hebben we een manier nodig om de bestandsbeschrijving van 7 (of 8) te dupliceren naar stdin:
while read b1 <&7 ... read b2 <&8 ...
Merk op dat read een -u optie heeft om een bestandsbeschrijving op te geven, aan u de keuze.
Bash kan op een gelijkaardige manier uitvoer omleiden naar bestanden. Raadpleeg voor meer informatie de man pagina's van bash.
Wanneer je sudo gebruikt om commando's als root uit te voeren, loop je tegen "Toegang geweigerd" problemen wanneer een deel van de pipeline of een deel van het commando met root toegangsrechten werkt.
Het volgende mislukt met "Toegang geweigerd" omdat het bestand enkel door de root beschreven kan worden:
echo 12000 > /proc/sys/vm/dirty_writeback_centisecs
Het volgende mislukt eveneens:
sudo echo 12000 > /proc/sys/vm/dirty_writeback_centisecs
Het echo programma werkt door sudo als root, maar de shell die de echo uitvoer doorstuurt naar het root bestand werkt nog steeds als gewone gebruiker.
De huidige shell start het doorsturen voor het uitvoeren van het sudo commando.
De oplossing bestaat uit het uitvoeren van de volledige pipeline door sudo.
Er zijn verschillende manieren, dit is er één van:
echo "echo 12000 > /proc/sys/vm/dirty_writeback_centisecs" | sudo sh
Op deze manier kan je alles wat je als root wilt uitvoeren voor het pipe teken typen en via | sudo sh uitvoeren. Deze methode werkt eveneens voor complexe root commando's die je echter beter grondig bekijkt voor je ze als root uitvoert, je weet maar nooit.
Om de interrupts (treden op als een hardware-onderdeel de software onderbreekt om dringend hardwaredata te verwerken) te zien, gebruik je het volgende commando:
watch -n1 "cat /proc/interrupts"
Every 1,0s: cat /proc/interrupts Sat Mar 14 14:54:15 2009
CPU0 CPU1
0: 51 21 IO-APIC-edge timer
1: 0 4 IO-APIC-edge i8042
3: 0 2 IO-APIC-edge
4: 0 3 IO-APIC-edge
7: 1 0 IO-APIC-edge
8: 235 124736 IO-APIC-edge rtc0
9: 0 0 IO-APIC-fasteoi acpi
12: 0 7 IO-APIC-edge i8042
14: 2886 33898 IO-APIC-edge pata_amd
15: 0 0 IO-APIC-edge pata_amd
20: 79575 101 IO-APIC-fasteoi ohci_hcd:usb2
21: 2 256 IO-APIC-fasteoi ehci_hcd:usb1
22: 1089 135 IO-APIC-fasteoi sata_nv, HDA Intel
23: 281432 17070 IO-APIC-fasteoi sata_nv
4346: 353039 2005 PCI-MSI-edge eth0
NMI: 0 0 Non-maskable interrupts
LOC: 1923223 2568488 Local timer interrupts
RES: 291097 297903 Rescheduling interrupts
CAL: 3094 1025 function call interrupts
TLB: 81419 81929 TLB shootdowns
TRM: 0 0 Thermal event interrupts
THR: 0 0 Threshold APIC interrupts
SPU: 0 0 Spurious interrupts
Het n1 argument van watch zorgt ervoor dat het commando elke seconde uitgevoerd wordt.
Ik gebruik al jaren bash, en toch beheers ik niet alle command line sneltoetsen. Een manier om ze in de vingers te krijgen, is gebruik te maken van Notities (gele blaadjes die je op het bureaublad plaatst) met een sneltoets. Na verloop van tijd kan je de sneltoets op de notitie dan vervangen door een andere sneltoets.
- Hier volgende enkele kandidaten:
Ctrl-renCtrl-s: Start respectievelijk een achterwaartse of voorwaartse zoekactie in de commandogeschiedenis.Ctrl-jenCtrl-g: Verlaat de zoekactie met respectievelijk de gevonden regel of de oorspronkelijke regel.Alt-.ofESC en daarna .: Beide sneltoetsen voegen op de cursorpositie het laatste argument van het laatste commando in. Dit is zeer handig bij het aanpassen en verplaatsen van bestanden.Alt-Ctrl-y: Voeg op de cursorpositie het eerste argument van het vorige commando in. Als je het n-de argument wilt, druk je voordien Alt-n. M.a.w. Alt-2 Alt-Ctrl-y voegt het tweede argument van het vorige commando in. (Een pak toetsen om te onthouden, toch zijn ze af en toe handig.)Ctrl-wenAlt-backspace: Beide sneltoetsen verwijderen het woord voor de cursor. Ctrl-w stopt bij witruimten, Alt-backspace daarentegen stopt bij niet alfanumerieke tekens. Bij bestand.txt zal Ctrl-w alles verwijderen, terwijl Alt-backspace bestand. laat staan. Dit heeft dus voor de hand liggende toepassingen. (Het werkt ook met underscores.)
Met het hier voorgestelde script gaan we informatie van het internet halen. De informatie komt van WeatherBug.com. Dezelfde techniek kan je gebruiken om informatie uit naslagwerken, woordenboeken of vertalingen van het internet te halen. Het hier voorgestelde script haalt recente weersvoorspellingen op.
Het script is relatief eenvoudig maar ook beperkt.
Het toont enkel een beknopt overzicht van de voorspelling.
Als er meer informatie beschikbaar is, wordt dit aangeduid met de melding ...more.
Het script start je als volgt (wees geduldig, het ophalen van de voorspelling kan een tijd duren):
./weather.sh Bruges Belgium
Om de informatie van het internet te halen en te verwerken, gebruikt het script wget en sed. Hoewel dit script voor verbetering vatbaar is, kan het reeds gebruikt worden om de activiteiten van de volgende dagen te plannen :)
#!/bin/bash # # weather.sh - It's raining somewhere in the world :) # # 2008 - Mike Golvach - eggi@comcast.net # # Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States License # numargs=$# arg1=$1 arg2=$2 if [ $numargs -lt 1 ] then echo "Usage: $0 [YourZipCode|Town Country]" echo "Ex: $0 60015" echo "Ex: $0 Berlin Germany" exit 1 fi if [ $numargs -eq 2 ] then args=`echo $args|sed 's/ /\+/g'` elif [ $# -gt 2 ] then echo "Usage: $0 [YourZipCode|Town Country]" echo "Ex: $0 60015" echo "Ex: $0 Berlin Germany" exit 1 fi echo args="$@" wget=/usr/bin/wget echo -n "Your Forecast:" if [ $numargs -eq 1 ] then $wget -nv -O - "http://weather.weatherbug.com/Common/SearchResults.html?is_search=true&nav_section=1&loc_country=WORLD&zcode=z6286&loc=$args" 2>&1|grep -w For|grep h3|grep $args|sed -e :a -e 's/<[^>]*>/ /g;/</N;//ba' -e 's/$/\n/' $wget -nv -O - "http://weather.weatherbug.com/Common/SearchResults.html?is_search=true&nav_section=1&loc_country=WORLD&zcode=z6286&loc=$args" rel="nofollow" 2>&1|sed -e :a -e 's/<[^>]*>/ /g;/</N;//ba' -e 's/$/\n/'|sed -e '1,/Your Forecast/d' -e '/7-Day Forecast/,$d'|sed -e '/^[ \t]*$/d' -e '/^$/N;/\n$/D' -e 's/[ \t]*more/... more\n/'|sed 's/°/Degrees/g' else echo " For $arg1, $arg2" $wget -nv -O - "http://weather.weatherbug.com/$2/$1-weather.html?nav_section=1&zcode=z6286" 2>&1|sed -e :a -e 's/<[^>]*>/ /g;/</N;//ba' -e 's/$/\n/'|sed -e "1,/Your Forecast for $arg1, $arg2/d" -e '/7-Day Forecast/,$d'|sed -e '/^[ \t]*$/d' -e '/^$/N;/\n$/D' -e 's/[ \t]*more/... more\n/'|sed 's/°/Degrees/g' fi exit 0
Met de hulpprogramma's poppler-tools en psutils kan je een aantal pagina's uit een PDF document afzonderen.
Als je bijvoorbeeld de pagina's 11 tot en met 14 van het PDF document kiwi.pdf wilt afzonderen, gebruik je het volgende commando:
pdftops kiwi.pdf - | psselect 11-14 | ps2pdf - kiwi-p11-14.pdf
Het pdftops (of pdf2ps) commando zet het PDF document om naar PostScript; het psselect commando selecteert de relevante pagina's uit de PostScript, en het ps2pdf commando zet de PostScript terug om naar een nieuw PDF document.
De interactie met de Linux Bash shell wordt aangenamer als je gebruik maakt van PS1, PS2, PS3, PS4, en PROMPT_COMMAND. PS staat voor prompt statement. Het aanpassen van deze omgevingsvariabelen bespreken we met behulp van eenvoudige voorbeelden.
1. PS1 - Standaard interactieve prompt
De standaard prompt in Linux kan aangepast worden tot een bruikbaar en informatief alternatief. In openSUSE 11.1 is PS1 standaard gelijk aan “$(ppwd \l)\u@\h:\w> ”, wat de gebruikersnaam, computernaam en de huidige map toont. Laat ons dit aanpassen om de shellnaam en -versie te tonen en daarna terug te herstellen naar de standaard.
dany@linux-frqe:~> export PS1="\s-\v\$ "
bash-3.2$ export PS1="$(ppwd \l)\u@\h:\w> "
dany@linux-frqe:~>- Een greep uit de PS1 codes:
- \u - Gebruikersnaam
- \h - Computernaam
- \w - Volledig pad van de huidige map. Wanneer je in de persoonlijke map werkt, zie je ~.
- Merk op dat er op het einde van de PS1 waarde een spatie staat. Veel mensen houden van deze spatie omdat het de leesbaarheid bevordert.
Maak deze instellingen permanent door export PS1="\s-\v\$ " toe te voegen aan .bashrc (of) .bash_profile.
2. PS2 - Voortzetting interactieve prompt
Een zeer lang linux commando kan in verschillende regels opgesplitst worden door de regels te laten eindigen op \. De standaard interactieve prompt voor een multi-regel commando is "> ". Laat ons dit aanpassen naar "vervolg-> " door gebruik te maken van de PS2 omgevingsvariabele:
dany@linux-frqe:~> tar czvf backup.tar.gz \
> bin \
> Desktop \
> public_html
dany@linux-frqe:~> export PS2="vervolg-> "
dany@linux-frqe:~> tar czvf backup.tar.gz \
vervolg-> bin \
vervolg-> Desktop \
vervolg-> public_htmlPersoonlijk vind ik dat het opsplitsen van lange commando's op verschillende regels de leesbaarheid ten goede komt. Sommigen vinden het opsplitsen van lange commando's juist storend. Wat je er ook over denkt, je hebt de keuze.
PS3 - Prompt gebruikt door “select” in shell scripts
Je kan met behulp van de PS3 omgevingsvariabele een eigen prompt maken om binnen een select lus in een script te gebruiken.
Shell script en uitvoer zonder PS3: (niet vergeten het script met het commando chmod +x ps3.sh uitvoerbaar te maken)
dany@linux-frqe:~> cat ps3.sh
select i in maandag dinsdag woensdag stop
do
case $i in
maandag) echo "Maandag";;
dinsdag) echo "Dinsdag";;
woensdag) echo "Woensdag";;
stop) exit;;
esac
done
dany@linux-frqe:~> ./ps3.sh
1) maandag
2) dinsdag
3) woensdag
4) stop
#? 1
Maandag
#? 4En nu met een PS3 omgevingsvariabele:
dany@linux-frqe:~> cat ps3.sh
PS3="Selecteer een dag (1-4): "
select i in maandag dinsdag woensdag stop
do
case $i in
maandag) echo "Maandag";;
dinsdag) echo "Dinsdag";;
woensdag) echo "Woensdag";;
stop) exit;;
esac
done
dany@linux-frqe:~> ./ps3.sh
1) maandag
2) dinsdag
3) woensdag
4) stop
Selecteer een dag (1-4): 1
Maandag
Selecteer een dag (1-4): 4PS4 - Gebruikt door “set -x” om uitvoer vooraf te gaan
De PS4 omgevingsvariabele staat in voor de prompt bij het uitvoeren van een shell script in debug mode.
Shell script en uitvoer zonder PS4:
dany@linux-frqe:~> cat ps4.sh
set -x
echo "PS4 demo script"
ls -l /etc/ | wc -l
du -sh ~dany@linux-frqe:~> ./ps4.sh
+ echo 'PS4 demo script'
PS4 demo script
+ wc -l
+ ls -l /etc/
278
+ du -sh /home/dany
29G /home/danyShell script en uitvoer met PS4:
dany@linux-frqe:~> cat ps4.sh
set -x
echo "PS4 demo script"
ls -l /etc/ | wc -l
du -sh ~dany@linux-frqe:~> ./ps4.sh
+ echo 'PS4 demo script'
PS4 demo script
+ wc -l
+ ls -l /etc/
278
+ du -sh /home/dany
29G /home/dany- De PS4 die in het onderstaande voorbeeld wordt gebruikt, gebruikt de volgende twee codes:
- $0 - de naam van het script
- $LINENO - toont het huidige regelnummer in het script
dany@linux-frqe:~> cat ps4.sh
export PS4='$0.$LINENO+ '
set -x
echo "PS4 demo script"
ls -l /etc/ | wc -l
du -sh ~dany@linux-frqe:~> ./ps4.sh
./ps4.sh.3+ echo 'PS4 demo script'
PS4 demo script
./ps4.sh.4+ ls -l /etc/
./ps4.sh.4+ wc -l
278
./ps4.sh.5+ du -sh /home/dany
29G /home/danyPROMPT_COMMAND
Bash shell voert de inhoud van PROMPT_COMMAND uit, juist voor het tonen van de PS1 variabele.
dany@linux-frqe:~> export PROMPT_COMMAND="date +%k:%m:%S" 14:02:04 dany@linux-frqe:~>Als je de uitvoer van PROMPT_COMMAND in dezelfde regel als PS1 wilt opnemen, gebruik je echo -n:
dany@linux-frqe:~> export PROMPT_COMMAND="echo -n [$(date +%k:%m:%S)]" [14:02:01]dany@linux-frqe:~>
Met de commando's kill en ps kan je bepalen of een proces al dan niet bestaat door na het uitvoeren van een kill of ps commando $? te controleren op succes of mislukken.
kill -0 kan echter mislukken bij een aanwezig proces. Dit komt voor als de gebruiker onvoldoende rechten heeft om het betreffende proces te benaderen (voorbeeld: kill -0 1).
Om in een script in stilte (zonder meldingen) te testen of een proces bestaat, gebruik je
ps -p 1 > /dev/null
echo $?Hier test het ps commando of het proces met PID 1 bestaat.
Met netstat kan je programma's opsporen die een verbinding met andere computers maken:
netstat -tpe
Active Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State User Inode PID/Program name
tcp 0 0 localhost:33817 localhost:sunrpc TIME_WAIT root 0 -
tcp 0 0 192.168.0.172:54053 21-59.182.62.static:ftp ESTABLISHED dany 356516 21646/dolphint20687Het -t argument toont enkel de TCP verbindingen. Het -p argument toont het PID en de naam van het programma dat de verbinding maakt. Het -e argument toont extra informatie zoals de gebruikersnaam waaronder het programma draait.
Om een deel van een afbeeding af te zonderen, kan je gebruik maken van het commando convert. Om een 100 beeldpunten breed stuk uit het midden van een afbeelding te snijden, gebruik je:
convert -crop 100x+0+0 fosdem.png uitsnede0.png
convert -crop +200+0 fosdem.png uitsnede1.png
convert +append uitsnede0.png uitsnede1.png resultaat.pngOm een 100 beeldpunten breed stuk van een afbeelding te dupliceren, gebruik je:
convert -crop 100x+100+0 fosdem.png uitsnede100.png
convert +append uitsnede0.png uitsnede100.png uitsnede100.png uitsnede1.png resultaat.pngMerk op dat in bovenstaande voorbeelden nergens de hoogte van de afbeelding werd opgegeven. Als je de hoogte in plaats van de breedte wilt gebruiken, zijn de te ondernemen stappen dezelfde, maar gebruik je -append in plaats van +append om de uitsnedes verticaal te plakken.
Soms moet je een aantal bestanden verwerken - sommige daarvan zijn gecomprimeerd, andere niet (denk aan log bestanden). Om geen twee varianten van het verwerkingsproces te moeten gebruiken, wikkel je het in een bash functie:
function data_source () {
local F=$1
# verwijder gz indien aanwezig
F=$(echo $F | perl -pe 's/.gz$//')
if [[ -f $F ]] ; then
cat $F
elif [[ -f $F.gz ]] ; then
nice gunzip -c $F
fi
}Wat het volgende mogelijk maakt:
for file in * ; do
data_source $file | ...
doneOf je nu te maken hebt met gzip gecomprimeerde bestanden of niet gecomprimeerde bestanden, vanaf nu kan je ze op dezelfde manier mentaal benaderen. Met een kleine extra inspanning kunnen met bzip gecomprimeerde bestanden herkend en verwerkt worden.
Als je veel terminal tabs of scripts gebruikt die een verbinding naar dezelfde OpenSSH server opbouwen, kan je dit versnellen door te multiplexen. Bij multiplexen wordt de eerste verbinding gemaakt als master (hoofdverbinding) en gebruiken de daaropvolgende verbindingen dezelfde gedeelde TCP verbinding naar de server.
Als je nog geen configuratiebestand in de .ssh map van je persoonlijke map hebt, maak je er één met de toegangsrechten 600 (enkel lees- en schrijfrechten voor de eigenaar). Voeg de volgende regels toe:
Host * ControlMaster auto ControlPath ~/.ssh/master-%r@%h:%p
ControlMaster auto laat ssh een master starten als er nog geen gestart is.
Indien er wel al een master gestart is, wordt de reeds gestarte master gebruikt.
ControlPath is de plaats van de socket (gemeenschappelijke toegang) voor de ssh processen om onderling te communiceren.
De %r, %h en %p worden vervangen door uw gebruikersnaam, de host (computer) waarmee je verbinding maakt en het poort nummer - enkel ssh sessies van dezelfde gebruiker naar dezelfde computer via dezelfde poort kunnen een TCP verbinding delen, waardoor elke groep gemultiplexte ssh processen een aparte socket nodig hebben.
Om zeker te zijn dat het werkt, start je een ssh sessie. Open daarna in een ander venster een nieuwe verbinding met de -v optie:
~$ ssh -v voorbeeld.org echo "hi"
In plaats van de uitgebreide verbose berichten van een gewone ssh sessie, krijg je enkele regels, met op het einde:
debug1: auto-mux: Trying existing master
hi
Als je een verbinding moet opbouwen met een oudere ssh versie die geen gemultiplexte verbindingen ondersteund, maak je een aparte Host sectie:
Host antiek.voorbeeld.org ControlMaster no
Voor meer informatie, zie man ssh en man ssh_config.
Hoewel heel wat energie en kennis in openSUSE samengebracht werd, kunnen de ontwikkelaars niet elk probleem voorzien en opvangen. Hier bepreek ik enkele ondervonden problemen en hun oplossing.
Google en Konqueror
Bij het intypen van een zoekwoord in het tekstvak bovenaan rechts. Gaat Google op zoek naar het ingegeven zoekwoord op google.nl. Voor Vlaanderen kan je beter gebruik maken van de nederlandstalige google.be site.
- Grafische oplossing
- Menu Instellingen>Konqueror instellen, in de categorie Webkoppelingen selecteer je Google en wijzig je de Zoek-URI naar
http://www.google.be/search?q=\{@}&ie=UTF-8&oe=UTF-8. - Commando oplossing
mkdir -p /home/$USER/.kde4/share/kde4/services/searchproviders echo "[Desktop Entry]" > /home/$USER/.kde4/share/kde4/services/searchproviders/google.desktop echo "Type=Service" >> /home/$USER/.kde4/share/kde4/services/searchproviders/google.desktop echo "Name=Google" >> /home/$USER/.kde4/share/kde4/services/searchproviders/google.desktop echo "X-KDE-ServiceTypes=SearchProvider" >> /home/$USER/.kde4/share/kde4/services/searchproviders/google.desktop echo "Keys=gg,google" >> /home/$USER/.kde4/share/kde4/services/searchproviders/google.desktop echo "Query[nl]=http://www.google.be/search?q=\\\\{@}&ie=UTF-8&oe=UTF-8" >> /home/$USER/.kde4/share/kde4/services/searchproviders/google.desktop echo "Charset=utf8" >> /home/$USER/.kde4/share/kde4/services/searchproviders/google.desktop echo "Name[nl]=Google" >> /home/$USER/.kde4/share/kde4/services/searchproviders/google.desktop
VMware Workstation 6.5.1 en Player 2.5.1
Na de installatie van VMware kan je VMware opstarten, maar bij het opstarten van een virtuele machine krijg je de foutmelding Could not open /dev/vmmon. Dit kan je verhelpen door voor het opstarten van VMware de virtuele apparaten te herinitialiseren.
- Grafische oplossing
- Maak in de Desktop-map een Nieuwe Link to application... aan (rechtermuisklik) met de volgende kenmerken:
- Tabblad Algemeen als Pictogram bij Toepassingen het pictogram vmware-player of vmware-workstation
- Tabblad Algemeen als naam in het tekstvak VMware Player
- Tabblad Toepassing als Commando
su -c "/etc/init.d/vmware restart"; vmplayer - Tabblad Toepassing bij de Geavanceerde opties
In een terminal uitvoeren.
vmplayerdoorvmware. - Commando oplossing
echo '[Desktop Entry]' > /home/$USER/Desktop/VMware\ Player.desktop echo 'Exec=su -c "/etc/init.d/vmware restart"; vmplayer' >> /home/$USER/Desktop/VMware\ Player.desktop echo 'Icon=vmware-workstation' >> /home/$USER/Desktop/VMware\ Player.desktop echo 'StartupNotify=true' >> /home/$USER/Desktop/VMware\ Player.desktop echo 'Terminal=true' >> /home/$USER/Desktop/VMware\ Player.desktop echo 'Type=Application' >> /home/$USER/Desktop/VMware\ Player.desktop echo 'X-DBUS-StartupType=none' >> /home/$USER/Desktop/VMware\ Player.desktop echo 'X-KDE-SubstituteUID=false' >> /home/$USER/Desktop/VMware\ Player.desktop echo 'X-SuSE-translate=true' >> /home/$USER/Desktop/VMware\ Player.desktop
DVD(CD)station activeren voor gebruikers
Hier hebben ze bij openSUSE iets over het hoofd gezien. Het DVD(CD)station kan door gewone gebruikers niet gebruikt worden om muziek en films af te spelen of om DVD(CD)'s te branden. Het DVD(CD)station kan enkel door de gebruiker root en de leden van de groep disk gebruikt worden.
- Grafische oplossing
- Start K menu > Computer > YaST.
- Start in de categorie Beveiliging en gebruikers de module Gebruikers- en groepenbeheer.
- Selecteer de gebruiker die toegang tot het DVD(CD)station moet krijgen en klik op de knop Bewerken.
- Op het tabblad Details plaats je een vinkje bij de Extra groepen cdrom en disk.
- Bevestig het bewerken en het Gebruikers- en groepsbeheer.
- Na het opnieuw aanmelden heeft de aangepaste gebruiker volledige toegang tot het DVD(CD)station.
- Commando oplossing
su -c "usermod -G disk,cdrom,dialout,video $USER"
OpenOffice.org op x86_64
Na de installatie van openSUSE 11.1 bleek op mijn x86_64 computer met 4 gigabyte geheugen OpenOffice niet op te starten onder KDE. Op mijn laptop met een 686 processor bleken er geen problemen te zijn. Op de volgende manier kan je op een x86_64 installatie de OpenOffice pakketten vervangen door de 32bits versie:
- Grafische oplossing
- Start K Menu > Computer > Software installeren
- Zoek de volgende pakketten, selecteer ze en pas de Versie (tabblad) aan naar i586.
OpenOffice_org OpenOffice_org-Quickstarter OpenOffice_org-base OpenOffice_org-base-extensions OpenOffice_org-calc OpenOffice_org-calc-extensions OpenOffice_org-components OpenOffice_org-draw OpenOffice_org-draw-extensions OpenOffice_org-filters OpenOffice_org-filters-optional OpenOffice_org-impress OpenOffice_org-impress-extensions OpenOffice_org-kde OpenOffice_org-libs-core OpenOffice_org-libs-extern OpenOffice_org-libs-gui OpenOffice_org-mailmerge OpenOffice_org-math OpenOffice_org-pyuno OpenOffice_org-ure OpenOffice_org-writer OpenOffice_org-writer-extensions
- Commando oplossing
su -c "zypper install OpenOffice_org.i586 OpenOffice_org-Quickstarter.i586 OpenOffice_org-base.i586 OpenOffice_org-base-extensions.i586 OpenOffice_org-calc.i586 OpenOffice_org-calc-extensions.i586 OpenOffice_org-components.i586 OpenOffice_org-draw.i586 OpenOffice_org-draw-extensions.i586 OpenOffice_org-filters.i586 OpenOffice_org-filters-optional.i586 OpenOffice_org-impress.i586 OpenOffice_org-impress-extensions.i586 OpenOffice_org-kde.i586 OpenOffice_org-libs-core.i586 OpenOffice_org-libs-extern.i586 OpenOffice_org-libs-gui.i586 OpenOffice_org-mailmerge.i586 OpenOffice_org-math.i586 OpenOffice_org-pyuno.i586 OpenOffice_org-ure.i586 OpenOffice_org-writer.i586 OpenOffice_org-writer-extensions.i586"
ATI grafische kaarten
openSUSE 11.1 gebruikt zoals alle recente distributies de fel verbeterde open source driver radeonhd.
Deze werkt in 2D mode perfect voor mijn beide computers.
In 3D mode werkt de driver uitstekend op mijn 32bit laptop met een Mobility Radeon X1600 grafische kaart maar weigert hij 3D diensten aan te bieden op mijn 64bits Desktop computer met een Radeon X1950 grafische kaart.
Na het toevoegen van de Softwarebron met de fglrx-driver (van ATI zelf) en het installeren ervan, bleek ook deze driver geen 3D diensten aan te bieden.
Het probleem zit in het feit dat de 64bits driver de 32bits 3D functies gebruikt, wat niet lukt waardoor de 3D functies automatisch terug uitgeschakeld worden.
Met een eenvoudige truc kan je de 64bits driver dwingen de 64bits 3D functies te gebruiken (zie oplossingen).
Opmerking: de hier gepresenteerde oplossing werkt bij mij, maar dit is geen garantie dat het op uw computer ook werkt.
M.a.w. als het misgaat kan het zijn dat je openSUSE 11.1 opnieuw moet installeren.
- Grafische fglrx-driver installatie en 64bits 3D oplossing
- Start K menu > Computer > Software installeren
- Menu Configuratie > Installatiebronnen...
- Knop Toevoegen > URL opgeven... > Verder
- Geef als Installatiebronnaam ATI in.
- Geef als URL http://www2.ati.com/suse/11.1 in.
- Bevestig het toevoegen van de Softwarebron.
- Accepteer het dialoogvenster Software installeren. De pakketten ati-fglrxG01-(kernel-module-type) en x11-video-fglrxG01 worden daarbij automatisch gedownload en geïnstalleerd.
- Start een Terminal.
- Om root te worden typ je het commando
sugevolgd door Return en het root-wachtwoord. - Om zeker te spelen, kopieer je de werkende configuratie met het commando
cp /etc/X11/xorg.conf /etc/X11/xorg.conf.bak - Je activeert de driver met het commando
sax2 -r -m 0=fglrx - Na een kort verblijf in de terminal mode (zwart scherm) schakel je automatisch terug naar de grafische mode. Bevestig daar het SaX2 dialoogvenster en sla daarbij de nieuwe configuratie op.
- Om op een 64bits systeem de 3D diensten van de driver te kunnen gebruiken, maak je voor de zekerheid een kopie van de 32bits functies met het commando
mv /usr/lib/dri/fglrx_dri.so /usr/lib/dri/fglrx_dri.so.ori - De 32bits functies vervang je door de 64bits functies met het commando
ln -s /usr/lib64/dri/fglrx_dri.so /usr/lib/dri/fglrx_dri.so - En dan nu het kritieke moment. Herstart de computer met het commando
reboot
- fglrx-driver installeren en 64bits 3D oplossing met commando's
su zypper sa http://www2.ati.com/suse/11.1 ati zypper in x11-video-fglrxG01 cp /etc/X11/xorg.conf /etc/X11/xorg.conf.bak sax2 -r -m 0=fglrx mv /usr/lib/dri/fglrx_dri.so /usr/lib/dri/fglrx_dri.so.ori ln -s /usr/lib64/dri/fglrx_dri.so /usr/lib/dri/fglrx_dri.so reboot
Misschien werkt de truc met het vervangen van de 32bits 3D functies door de 64bits 3D functies ook voor de radeonhd driver (maar aangezien ik de fglrx-driver reeds had geïnstalleerd, heb ik dit niet verder onderzocht).
Met de 3D functies kan je genieten van 3D games, Desktop-effecten (K menu > Systeeminstellingen > Bureaublad), enz.
Nano is één van de kleinste en gebruiksvriendelijkste teksteditors voor de terminal.
Op openSUSE 11.1 installeer je nano met het commando:
su -c "zypper install nano"
Mensen die in plaats van geavanceerde IDE's zoals Emacs of Vim Nano gebruiken om C, Bash, html of andere broncode aan te passen, kunnen eigenlijk niet zonder syntax highlighting.
Om highlighting voor verschillende programmeertalen in te schakelen, moet je het bestand ~/.nanorc aanpassen (of aanmaken, indien het nog niet bestaat) en aanvullen met regels zoals:
include "/usr/share/nano/c.nanorc"
include "/usr/share/nano/python.nanorc"
include "/usr/share/nano/sh.nanorc"
Deze drie regels voegen de regels voor het benadrukken van C (c.nanorc), Python (python.nanorc) en Bash (sh.nanorc) toe.
De beschikbare bestanden met benadrukregels kan je opvragen met:
ls /usr/share/nano/
Wat op openSUSE 11.1 met Nano 2.1.5 het volgende toont:
asm.nanorc gentoo.nanorc mutt.nanorc pov.nanorc tex.nanorc
awk.nanorc groff.nanorc nanorc.nanorc python.nanorc xml.nanorc
c.nanorc html.nanorc patch.nanorc ruby.nanorc
css.nanorc java.nanorc perl.nanorc sh.nanorc
debian.nanorc man.nanorc php.nanorc tcl.nanorcDit zijn standaard benadrukregels die bij Nano horen. Je kan natuurlijk op zoek gaan naar andere regels (Internet) en deze gebruiken, bijvoorbeeld regels die beter passen bij de door u gebruikte achtergrond.
 Hiernaast een voorbeeld van hoe in C de syntax met de standaard regels benadrukt wordt.
Hiernaast een voorbeeld van hoe in C de syntax met de standaard regels benadrukt wordt.
Het configuratiebestand ~/.nanorc laat u toe Nano's standaardgedrag aan te passen.
Bij het starten van Nano worden de configuratie opties uit /etc/nanorc ingelezen, en daarna de individuele uit het ~/.nanorc bestand (indien aanwezig).
Om een overzicht van de verschillende opties te krijgen, gebruik je het commando:
man nanorc
Je kan de benadrukcode op het einde van het configuratiebestand ~/.nanorc invoegen. Je kan op de site Nano Syntax Highlighting verschillende benadrukregels vinden.